
AI agents are increasingly being used to autonomously handle recurring or complex tasks, from ordering equipment to assisting customer support to planning supply chains. However, as organizations deploy more of these agents, they often end up siloed—each built on different frameworks or by different vendors, unable to communicate or coordinate with one another. Google’s Agent2Agent (A2A) Protocol is a newly launched open standard designed to break down these silos.
A2A enables multiple AI agents to interoperate seamlessly, securely exchanging information and coordinating actions even if they were developed by different providers or use different underlying technologies. Backed by contributions from over 50 technology partners (including Atlassian, Box, LangChain, Salesforce, ServiceNow, and more), A2A is poised to become a common “language” for agent collaboration across the industry. By allowing agents to “talk” to each other, A2A aims to increase overall autonomy and productivity of AI systems while lowering long-term integration costs.
A conceptual illustration of the Agent2Agent (A2A) protocol connecting AI agents across a network. A2A provides a standardized way for agents to communicate regardless of their build or vendor, ushering in more collaborative and powerful multi-agent ecosystems.
In the evolving AI landscape, this kind of interoperability is critical. Rather than treating each agent as an isolated “app,” A2A treats them as part of a broader ecosystem that can dynamically collaborate on tasks. This is especially important in enterprise settings where a single workflow (such as processing a customer request or fulfilling an order) might benefit from the expertise of multiple specialized agents.
Agent2Agent (A2A) makes such collaboration possible by defining a common protocol for communication, much like how HTTP enables any web browser to talk to any web server. The following sections provide a deep dive into what A2A is, how it works, and how you can get started using it to build your own multi-agent solutions.
Presentation of the Framework
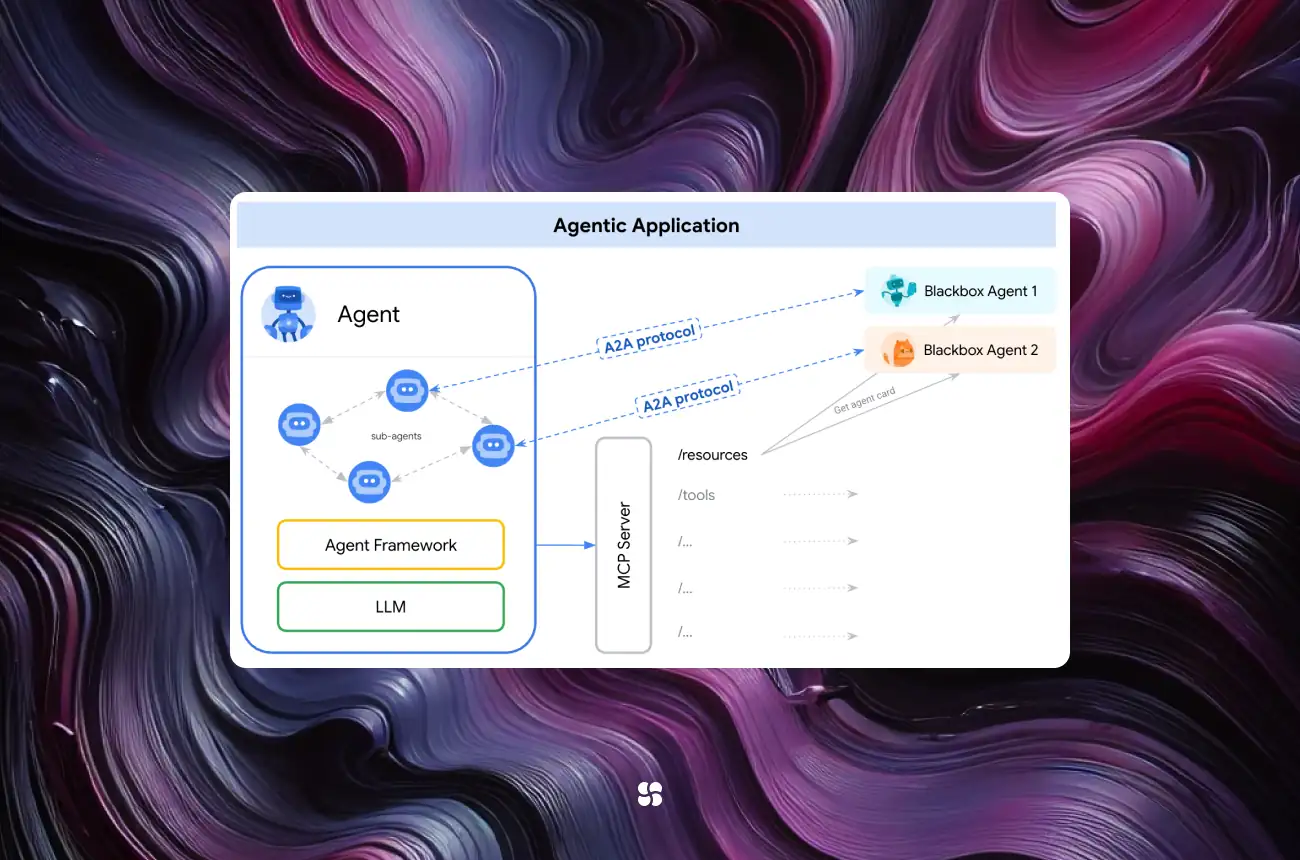
What is A2A? At its core, A2A is an open protocol (an agreed-upon set of messages and procedures) that lets independent AI agents communicate and work together. It is complementary to Anthropic’s Model Context Protocol (MCP) – whereas MCP is like a “toolbox” protocol that provides models with tools and context (a standardized way for AI agents to access external tools or information), A2A focuses on the agents themselves talking to each other. In other words, A2A connects agents to other agents, while MCP connects agents to resources and tools.
Both protocols share a vision of enhancing AI capabilities in a modular way, and they can operate together: for example, an AI agent might use MCP to gather information or execute a tool, then use A2A to collaborate with another agent using that information. A2A does not replace MCP but builds on it – together they provide a more complete ecosystem for multi-agent systems (MCP handling tools and context, A2A handling agent-to-agent interplay).
Architecture and Key Concepts: In an A2A-enabled system, any given agent can play one of two roles during an interaction: a client agent or a remote agent. The client agent is the one initiating a task (on behalf of a user or a higher-level goal) and formulating requests, while the remote agent is the one receiving the request and acting on it to produce a result. These roles are not fixed – an agent could be a client in one interaction and a remote agent in another, depending on who initiates the communication. The protocol defines a standard message format and workflow for this interaction, revolving around a unit of work called a Task.
Some fundamental components of the A2A framework include:
- Agent Card: Every A2A-compliant agent exposes a public metadata file (typically at the URL
/.well-known/agent.json) describing itself The Agent Card contains the agent’s identity and description, the capabilities or skills it offers, the URL endpoint where it can be reached, and any authentication requirements for accessing it. This serves as a discovery mechanism – a client agent can fetch another agent’s card to learn how to communicate with it. (It’s analogous to a service listing its API description for others to consume.) - A2A Server: This refers to an agent implementation that runs an HTTP(S) server endpoint following the A2A protocol specification. In practice, an “A2A server” is an agent waiting for incoming requests from other agents. Google’s reference implementation uses standard web tech: the agent exposes a RESTful HTTP API (using JSON for data) with routes to handle tasks, and uses Server-Sent Events (SSE) for real-time updates. Under the hood, A2A messages conform to a JSON-RPC structure carried over HTTP, meaning it builds on familiar web standards (HTTP, JSON) and techniques like long polling or SSE for streaming updates.
- A2A Client: This is the counterpart that initiates calls to an A2A server. An A2A client could be another agent or any application that wants to utilize an agent’s capabilities. The client uses the information in the Agent Card to know where and how to send requests. For example, a client agent might read that a remote agent’s card lists an endpoint
https://sales.example.com/a2awith certain supported methods, and then the client can send a task request to that endpoint. - Task: A Task is the central object in A2A – it represents a single unit of work or conversation between agents. When a client agent needs something done, it will initiate a task by sending a request (e.g., an HTTP POST) to the remote agent’s
tasks/sendendpoint, including details like a unique Task ID and an initial message (often corresponding to a user’s query or instruction). The remote agent, acting as an A2A server, will create a new Task on its side and start processing it. Each Task has a lifecycle with defined states: for instance,submitted(just received),working(in progress),input-required(needs more info from client or user), and a terminal state such ascompleted(finished successfully with a result),failed, orcanceled. Throughout the task’s life, both agents stay in sync about its state. - Message: Communication within a task happens through messages exchanged between the client and remote agent. For example, the initial user request wrapped in a
tasks/sendcall is a message from the client side (role"user"in the protocol), and the remote agent’s answer would be a message from the agent side (role"agent"). If the task is multi-turn (requiring back-and-forth), the client can send follow-up messages (with the same Task ID) and the agent can reply accordingly. A2A formalizes this turn-taking so that even complex dialogues can be carried out between agents. - Part and Artifact: In A2A’s message schema, each message may consist of one or more parts. A Part is a piece of content that can be of different types – for example, a
TextPartfor plain text, aFilePartfor binary files or images (with data or a link), or aDataPartfor structured JSON data (like a form or table). This granularity allows rich interactions. An agent’s response might include a text explanation plus a data table as separate parts within one message. An Artifact is similar in structure but represents a larger outcome or deliverable of a task. For instance, if an agent’s job is to produce a report or an image, that final output would be an Artifact (containing one or more parts, such as the file content and metadata about it). By modeling content in parts and artifacts, A2A enables agents to negotiate and handle complex outputs – not just text, but images, forms, or other media – in a structured way.
Using these components, agents interoperate through a well-defined sequence. A typical A2A interaction flow goes like this:
- Discovery: The client agent locates the remote agent’s Agent Card (for example, by a known URL or service registry) and fetches it. The card tells the client what the remote agent can do and how to communicate with it (endpoints, supported message types, required auth, etc.).
- Initiation: The client agent starts a new task by sending a
tasks/sendrequest to the remote agent’s A2A server endpoint. This request includes a unique Task ID (generated by the client) and the initial message (often representing a user’s query or command). If the client expects a continuous stream of results (for a long-running task), it could use an alternativetasks/sendSubscribemethod to receive live updates. - Processing: The remote agent receives the task request and begins working on it. Depending on complexity, two patterns are possible: (a) Synchronous: for quick tasks, the remote agent can process immediately and return a final result in the HTTP response. (b) Asynchronous/Streaming: for longer tasks, the remote agent may quickly acknowledge the task and then stream progress updates back to the client (using Server-Sent Events). In streaming mode, the client stays subscribed to an event stream where the remote agent pushes TaskStatusUpdate events (e.g., “still working”, “needs input”) and TaskArtifactUpdate events (partial results or outputs). This allows real-time feedback for lengthy jobs.
- Interaction (if needed): Sometimes the task cannot be completed without additional information – for example, a remote agent might require the user to clarify a request or fill out a form (think of an agent that needs an approval or additional parameters). In such cases, the remote agent can pause the task in an
input-requiredstate and send back a message (or Artifact) requesting more input. The client (or ultimately the end-user via the client agent) can then respond by sending anothertasks/sendmessage with the required info, continuing the same task. A2A’s protocol ensures these messages all tie back to the same Task ID and context, enabling multi-turn dialogues between agents as they collaborate to complete the task. - Completion: Eventually, the task reaches a terminal state—either completed successfully (with a final result Artifact), or failed (if something went wrong), or canceled (if aborted). The remote agent’s final response (or stream of responses) will indicate the outcome and include any output data (results, files, etc.). The client agent can then present the result to the user or move on to the next steps in a workflow.
Throughout this process, A2A handles important details like authentication, error handling, and state management in a standardized way. For instance, A2A is designed to be secure by default – it supports enterprise authentication schemes equivalent to those in OpenAPI (e.g., API keys, OAuth tokens), so agents can verify and authorize each communication. Also, because it’s built on web standards, it can integrate with existing logging, monitoring, and scaling infrastructure that organizations already use for web services.
Notably, A2A is modality-agnostic: it is not limited to text-only interactions. Agents can negotiate and exchange rich content. If one agent only supports text and another tries to send an image part, the protocol includes a way to gracefully handle that (e.g. the agent could decline or request an alternative format). This flexibility prepares A2A for a future where agents might exchange images, audio, or even video content as part of their collaboration.
Relation to MCP: To put A2A in context, consider a complex agentic application. MCP (Model Context Protocol) would be used when an agent needs to use a tool or fetch external context – for example, calling a calculator API or querying a database for information. A2A, on the other hand, is used when an agent needs help from another agent – for example, asking a specialized agent to perform a sub-task or provide a service. An AI assistant might use MCP to access a knowledge base and also use A2A to consult another agent that handles, say, calendar scheduling. By complementing each other, A2A + MCP enable both vertical integration (agent-to-tool via MCP) and horizontal integration (agent-to-agent via A2A) in the multi-agent ecosystem. As Google’s team describes, “A2A empowers developers to build agents capable of connecting with any other agent built using the protocol… businesses benefit from a standardized method for managing their agents across diverse platforms”. In short, A2A extends an agent’s reach beyond its own silo, while MCP extends an agent’s reach into external tools – together helping break traditional barriers in AI system design.
Benefits of A2A
Why is A2A important, and what advantages does it offer for developers and organizations? The design of the Agent2Agent protocol was guided by several key principles that translate into direct benefits. Here are some of the most significant benefits of A2A:
- Interoperability and Ecosystem Synergy: At its heart, A2A is about interoperability. It gives your AI agents a common language to communicate, no matter what framework or vendor they come from. This means you can plug in a new agent (from a third-party service or an open-source project) and have it collaborate with your existing agents with minimal custom integration. This interoperability unlocks multi-agent synergy – agents can form teams, each bringing unique capabilities, to solve complex tasks together. For example, an agent built with one library (say, a LangChain-based QA agent) can query another built on a different platform (say, a SAP AI agent for enterprise data) if both speak A2A. This benefit is already being realized by industry leaders: the protocol’s launch partners share a vision of agents seamlessly working across systems to automate workflows at unprecedented scale.
- Modularity and Flexibility: A2A promotes a modular architecture for AI solutions. Instead of one monolithic super-agent trying to do everything, you can compose solutions out of specialized agents that focus on specific tasks or domains. Each agent can be developed and maintained independently (possibly by different teams or organizations), and A2A will allow them to coordinate their efforts. This modular approach means you can upgrade or replace one agent (e.g., swap out your NLP agent for a newer one) without breaking the whole system, as long as the new agent also speaks A2A.In effect, agents become like microservices in a larger AI system. Google’s team explicitly wanted to “enable true multi-agent scenarios without limiting an agent to a tool” – in other words, an agent shouldn’t be confined to acting as just a tool in another’s prompt, but can be an active collaborator. A2A realizes this by treating each agent as a first-class entity that can initiate and handle rich dialogues, not just passive API calls.
- Ease of Integration (Built on Web Standards): A2A was deliberately built on existing popular standards – specifically HTTP for transport, JSON for data format, and JSON-RPC conventions for structuring calls. It also uses Server-Sent Events (SSE) for streaming updates, which is a well-established web mechanism. For developers, this is great news: there’s no exotic new technology to learn or proprietary library required. Any environment that can make an HTTP request and parse JSON can potentially participate in A2A. You can use your favorite web frameworks (FastAPI, Express.js, etc.) to implement A2A endpoints. This lowers the barrier to entry and accelerates integration into existing IT stacks. If your enterprise already has authentication, logging, and monitoring for HTTP services, A2A agents can plug right in. In short, A2A feels familiar by design, which makes adoption and integration much easier.
- Enterprise-Grade Security: Enterprises need their inter-service communications to be secure. A2A was designed with security from the ground up. It supports the same authentication schemes you would find in standard APIs (analogous to OpenAPI security schemes) – for instance, an Agent Card can specify that OAuth2 tokens or API keys must be provided by any client, ensuring only authorized agents can connect. Because it runs over HTTPS, you get encryption in transit. Moreover, by standardizing the auth patterns, it’s easier to manage credentials across a fleet of agents. The bottom line is that A2A aims to be “secure by default”, which is crucial when agents might be carrying out sensitive enterprise tasks or accessing private data on each other’s behalf.
- Support for Long-Running Tasks and Scalability: One of the challenges in complex workflows is that some tasks can take a long time, especially if humans are intermittently involved or if heavy processing is needed. A2A explicitly supports long-running and asynchronous tasks. Its streaming capabilities (via
tasks/sendSubscribeand SSE) allow an agent to work on a task for hours or even days, periodically informing the client of progress or waiting for input, without blocking or timing out a single HTTP request. This design makes the system robust and scalable: an agent can juggle many ongoing tasks from different clients concurrently, and clients can orchestrate complex workflows without worrying about dropped connections. For example, an agent could initiate a research task that involves multiple steps and human approvals; with A2A, that agent can update the status continuously and even hand the task back to the user for input at certain points (using the input-required state) This flexibility means A2A is suited for both quick interactions and marathon processes. As a bonus, the protocol’s ability to handle multi-turn exchanges and streaming results naturally scales to future demands (like integrating voice or video output). - Multi-Modal and Future-Proof: A2A is modality-agnostic and built to handle a variety of content types (text, data, files, images, etc.). This is a forward-looking benefit. As AI agents evolve, they may need to share things beyond text — imagine design agents exchanging graphic files, or robotics agents sharing sensor data. A2A’s flexible message part system means it can already accommodate those without a redesign. Furthermore, A2A is open-source and actively being improved by a broad community, which means it will continue to evolve. Google and its partners plan to extend the protocol for things like dynamic capability queries, richer negotiation of interaction modalities (like on-the-fly switching to audio), and more. By adopting A2A now, you’re investing in a future-proof standard that will likely incorporate more advanced features and remain compatible as the ecosystem grows.
In summary, A2A brings interoperability, modularity, ease of use, security, and scalability to multi-agent systems. It allows developers to focus on building intelligent agent capabilities without having to reinvent communication protocols for each new pair of agents. Just as TCP/IP enabled a diversity of computers to form the internet, A2A aspires to enable a diversity of AI agents to form collaborative networks of problem solvers.
Getting Started
Now that we understand what A2A offers, let’s look at how you can start using it. Google has open-sourced A2A on GitHub, providing documentation, a draft specification, and a set of sample agents and clients to help developers experiment with the protocol. In this section, we’ll cover setting up your environment, running the provided examples, and the first steps to getting an A2A agent up and running.
Installation and Setup: Since A2A is currently a protocol framework and not (yet) a one-line installable library, the easiest way to start is by cloning the official GitHub repository. The repository contains reference implementations and examples in both Python and JavaScript for key components. You’ll need a recent version of Python (3.12+ or 3.13+ is recommended in the docs) and/or Node.js if you plan to try the JavaScript side. The samples use a tool called “uv” (a unified Python environment manager) to run the code in isolated virtual environments. If you don’t have it, you can install it via pip (pip install uv) – it’s a handy tool that will automatically set up any needed dependencies when running the examples. Alternatively, you can manually create a Python virtual environment and install dependencies using the provided pyproject.toml or requirements in the repo (the uv tool just simplifies this process).
Once you have the repository and environment ready, you should have access to a suite of sample agents and sample host applications that Google has provided. These are found under the samples/ directory of the repo and showcase how A2A works in practice:
- Sample Agents (A2A Servers): Under
samples/python/agents/(and similarly insamples/js/for JavaScript), you’ll find a few ready-made agent implementations. Each of these is a self-contained agent that runs as an A2A server (listening for incoming tasks) and demonstrates different capabilities:- Google ADK Agent: An agent built with Google’s Agent Development Kit that (mock) fills out expense reports, demonstrating a multi-turn conversation with form-filling via A2A.
- LangGraph Agent: An agent that can convert currency using an external tool, demonstrating how an agent can use tools and stream partial updates (it leverages an LLM and a currency conversion API).
- CrewAI Agent: An agent that generates images from prompts, showcasing how non-text binary content (images) can be sent through A2A in multi-turn interactions.
- (There are also others like “GenKit” in the JS samples, etc., but the above give a sense.)
Each sample agent comes with its own README and can be run on a local port (by default they choose ports like 10000, 10001, etc., which you can override). They also each host anagent.jsonAgent Card for discovery. You can run these agents to simulate various specialized AI services in a multi-agent setup.
- Sample Host Apps (A2A Clients): Under
samples/python/hosts/you’ll find example client-side applications that act as the initiators of conversations with agents. These illustrate how to discover an agent and send it tasks:- Command-Line Interface (CLI): A simple terminal-based client that you can run to chat with a given A2A agent via text. You point it at an agent’s URL and it will fetch the agent’s card, then let you type messages which are sent as A2A tasks, printing out the agent’s responses to the console. This is great for quickly testing an agent’s capabilities or for debugging.
- Orchestrator Agent: This is a special “agent-as-client” – it’s an agent that can delegate tasks to other agents. Built on the Google ADK, it effectively acts as a multi-agent coordinator. The orchestrator maintains a collection of “remote agents” (it can load their Agent Cards, much like a user might load contacts) and can decide to forward user requests to one or more of those remote agents. This demonstrates how you might build a high-level agent that breaks a user’s request into sub-tasks handled by specialists. Under the hood, each remote agent in the orchestrator is represented by an A2A client component that proxies requests to the actual remote A2A server.
- Multi-Agent Web App: In the
demo/directory, there’s a web-based interface that brings everything together with a GUI. This web app (called “Agentspace” in the blog) allows a user to interact with a host/orchestrator agent in a chat UI, while dynamically adding or removing remote agents. It visualizes the conversations and even shows debug info like task states and the content of messages passed around. This is a powerful demo to see A2A in action with multiple agents at once.
First Run – “Hello World” with A2A: Let’s walk through a simple startup scenario to ensure everything is working:
1. Run a Sample Agent (Server): Choose one of the sample agents to run locally. For example, let’s start the LangGraph agent (the currency converter). In your terminal, navigate to the repository’s samples/python directory and run:
uv run agents/langgraphThis will launch the LangGraph agent’s A2A server, typically listening on http://localhost:10000 (check the console output for the exact port). The agent will also serve its Agent Card at http://localhost:10000/.well-known/agent.json. Now you have a live agent ready to talk!
2. Run the CLI Client: In another terminal (also in samples/python), run the CLI sample pointing it to the LangGraph agent:
uv run hosts/cli --agent http://localhost:10000This starts the interactive command-line client It will fetch the agent’s card (verifying the agent’s capabilities and connection) and then prompt you to enter messages.
3. Have a Conversation: Type a message or query for the agent. Since LangGraph’s specialty is currency conversion (and it showcases tool use), try something like:
convert 100 USD to EURHit enter, and watch the CLI. The client has sent your request as an A2A task to the agent. The LangGraph agent, upon receiving this, will likely call its internal tool to get conversion rates, possibly stream progress if it’s doing step-by-step reasoning, and finally return an answer. You should see a response appear in the CLI, for example:
Agent: 100 USD is approximately 92 EUR.You can continue the conversation (the CLI keeps the session open). For instance, you could ask a follow-up like “What about GBP?” and the agent can handle the multi-turn context, converting USD to GBP next. When you’re done, you can exit the CLI.
This simple exercise confirms that your environment is set up and that an A2A client and server can communicate. Underneath the hood, when you ran the CLI with --agent http://localhost:10000, it performed the discovery and negotiation automatically: it fetched http://localhost:10000/.well-known/agent.json, learned what the agent can do, then used tasks/send to send your query and awaited the result. The streaming was handled as well – if the agent had provided intermediate updates, the CLI would display them in real-time (for example, if an agent streamed a sentence gradually or sent multiple partial answers).
Setting Up Your Own Agent: After experimenting with the samples, you might want to create your own A2A agent. The easiest path is to take one of the sample agent templates and modify it. The core things you need to implement are:
- Define your Agent’s capabilities in an Agent Card: This could be a static JSON file served at
/.well-known/agent.jsonby your web framework. It should include fields like the agent’s name, description, the URL of its A2A endpoint, what authentication it expects (if any), and a list of capability tags or specific skills it has. The JSON schema for Agent Card is in the spec (and sample agents show examples of it). - Run an A2A Server Endpoint: Using a web framework (Flask/FastAPI in Python, Express in Node, etc.), set up the HTTP routes as defined by the A2A spec. The primary ones include
POST /tasks/send(and a similar route for subscribe if you support streaming) to receive new tasks,POST /tasks/cancelto allow clients to cancel a task, possiblyPOST /tasks/pushNotification/setif you enable push notifications, etc. Google’s sample A2AServer class (insamples/python/common) can be used or referenced – it essentially wraps a web server and handles the routing for you. You don’t have to start from scratch; you can use these common libraries to register your logic. - Implement Task Handling Logic: This is the “brain” of your agent – when it receives a task request, what does it do? For a trivial agent, it might just echo the input back. For something more useful, you’ll likely integrate an LLM or some service. For example, a question-answering agent might call an LLM with the user query, or an order-processing agent might call a database or another API. The A2A framework provides an AgentTaskManager utility (as seen in samples) to manage task state transitions (submitted -> working -> completed, etc.) and to send updates. You’ll write code that, given the input message, produces a result (possibly over time) and uses the A2A server’s hooks to output messages or artifacts back to the client. The sample agents are a great reference for this: e.g., the CrewAI agent shows how to take an image generation prompt, call an image API, and then stream back the result image as an Artifact part.
- Test with a Client: Once your agent is running, you can use the CLI or even just
curlcommands to test its A2A endpoints. For example, you couldcurl http://localhost:12345/.well-known/agent.jsonto see if the card is served correctly, andcurl -X POST http://localhost:12345/tasks/send -d '{...}'with a sample payload to simulate a task (though using the CLI or a proper client library is much easier than crafting raw JSON by hand).
Google has also hinted that they plan to simplify “Hello World” examples further, possibly with higher-level SDKs or easier setup, so keep an eye on the repo for updates.
Step-by-Step Real-World Example
To cement these concepts, let’s walk through a real-world scenario showcasing A2A in action. Imagine we are implementing a simplified travel booking assistant. In this scenario, a user wants to book a trip, which involves finding a flight and a hotel. We’ll use three agents, each with a distinct role, and see how A2A allows them to collaborate to fulfill the user’s request:
- Travel Planner Agent (Host) – This is the agent the user interacts with initially (via chat or voice). It doesn’t have specialist knowledge itself, but it knows how to break down the user’s request and delegate to the appropriate agents. It acts as an orchestrator using A2A (similar to the orchestrator in the sample host apps). Think of this as a virtual travel concierge that knows which experts to consult.
- Flight Finder Agent (Remote) – A specialized agent that can search for flights given some criteria (dates, destinations, etc.). Perhaps it’s connected to an flights API or uses a dataset of flights. It runs as an A2A server and advertises a capability like
"flight_search"in its Agent Card. - Hotel Finder Agent (Remote) – Another specialized agent that can search for hotel availability. It might use a hotels API. It also runs as an A2A server, advertising a
"hotel_search"capability in its card.
Use Case: “Book me a 3-day trip to Paris next month.” – The user tells this to the Travel Planner agent. This single request actually entails multiple sub-tasks: finding flights to Paris (and back), and finding a hotel for the stay. The Travel Planner will use A2A to accomplish this. Here’s how the process might go:
- User request to Host Agent: The Travel Planner agent (host) receives the user’s query “I want to travel to Paris for 3 days in May”. This agent parses the request and realizes it needs two pieces of information: flight options and hotel options. It identifies that it should ask the Flight Finder agent for flights, and the Hotel Finder agent for hotels.
- Discovery of Remote Agents: (In a real deployment, the Travel Planner would know the URLs of trusted agents or discover them via a registry.) Let’s say it knows the Flight Finder’s Agent Card is at
https://flights.example.com/.well-known/agent.jsonand the Hotel Finder’s athttps://hotels.example.com/.well-known/agent.json. The Travel Planner fetches these cards (if not already cached) to confirm their endpoints and capabilities include what it needs. - Delegating tasks via A2A: The Travel Planner now formulates two A2A tasks:
- It sends a
tasks/sendrequest to the Flight Finder agent’s endpoint (e.g.,POST https://flights.example.com/tasks/send) with a Task containing the details: “Find available flights from my city to Paris, departing May 10 and returning May 13” (for example). This will have a Task ID, saytask123. - In parallel, it sends a
tasks/sendto the Hotel Finder agent (e.g.,POST https://hotels.example.com/tasks/send) with a Task: “Find available hotel in Paris from May 10 to May 13 for 1 room”. This has a different Task ID, saytask124.
Because both remote agents support streaming, the Travel Planner usestasks/sendSubscribeto allow receiving updates as the search progresses. These HTTP calls are made asynchronously (the Travel Planner doesn’t block and wait; it can handle responses as they come).
- It sends a
- Remote Agents process tasks:
- The Flight Finder agent contacts a flight data source and finds, say, 3 flight options. It might stream partial results – for instance, as it finds each option, it sends a SSE event back. Once done, it marks task123 as completed with an Artifact containing the list of flight options.
- The Hotel Finder agent similarly checks hotels and streams back a few hotel options, then marks task124 completed with an Artifact of hotel choices.
During this time, the Travel Planner agent’s A2A client components are listening to the SSE updates. Let’s say each agent found a couple of options, and both tasks complete within a few seconds.
- Aggregation and response: The Travel Planner now has results from both sub-tasks. It could simply forward them to the user separately, but a smarter planner will aggregate and present a combined result. For example, it might choose the cheapest flight + hotel combo or at least format the suggestions nicely. Suppose it picks one flight and one hotel as a recommendation, or it lists a short summary of options. The Travel Planner then sends the final answer back to the user: e.g., “I found a flight on May 10 returning May 13 for $500 and a hotel for $150/night at Hotel XYZ. Would you like to book these?”. This message is presented via whatever interface the user is using (chat app, voice assistant, etc.), completing the initial query. All of this happened through A2A calls behind the scenes – the user only sees the Travel Planner as their single point of contact, but unbeknownst to them, two other agents collaborated to fulfill the request.
- Follow-up (multi-turn interaction): If the user has follow-up requests, the process continues. For instance, if the user says, “I’d prefer an evening flight,” the Travel Planner can take that input and perhaps re-query the Flight Finder agent (using the same Task ID
task123if it kept it open, or starting a new task) to filter for evening flights. A2A allows the Travel Planner to send additional messages on an existing task if it hasn’t been closed, which could be useful if the flight agent had paused for input (though in this case it completed; we’d likely start a new task or modify criteria and re-run). The key is that multi-turn dialog is maintained: each agent retains context through the Task lifecycle and the Travel Planner keeps track of which Task ID corresponds to which part of the user’s query.
Code Snippet (Pseudo-code): Below is a simplified pseudo-code sketch (in Python-style) of how the Travel Planner agent might implement the above logic using an A2A client library. This assumes we have some A2A client class to handle communication (such a class exists in the samples for Python, encapsulating SSE listening, etc.). This is for illustration purposes:
# Pseudo-code for Travel Planner Orchestration using A2A clients
from a2a_client import A2AClient # hypothetical helper from A2A samples
# Initialize A2A client for each remote agent (using their Agent Card URLs)
flight_agent = A2AClient("https://flights.example.com") # will GET /.well-known/agent.json
hotel_agent = A2AClient("https://hotels.example.com") # likewise
# User request comes in (could be via an API endpoint or chat interface)
user_request = "Book me a 3-day trip to Paris next month."
# Parse user request (in reality, use NLP to extract details; here we hardcode for example)
destination = "Paris"
start_date = "2025-05-10"
end_date = "2025-05-13"
# Formulate tasks for each agent
flight_task = flight_agent.create_task(
message = f"Find flights to {destination} from my city, depart {start_date}, return {end_date}."
)
hotel_task = hotel_agent.create_task(
message = f"Find hotels in {destination} from {start_date} to {end_date} for 1 person."
)
# Send tasks asynchronously and subscribe for streaming updates
flight_agent.send_task(flight_task, subscribe=True)
hotel_agent.send_task(hotel_task, subscribe=True)
# Wait for both tasks to complete (in practice, use event loop or callbacks for SSE events)
while not (flight_task.is_done() and hotel_task.is_done()):
# This loop would be event-driven; pseudo-coded here for clarity
if flight_task.has_update():
latest = flight_task.get_update()
print("Received flight update: ", latest)
if hotel_task.has_update():
latest = hotel_task.get_update()
print("Received hotel update: ", latest)
sleep(0.1) # tiny delay to simulate wait
# Aggregate results once done
if flight_task.status == "completed" and hotel_task.status == "completed":
flights = flight_task.result.artifact["flights"] # assume artifact contains a list
hotels = hotel_task.result.artifact["hotels"]
# Simple strategy: pick the first flight and first hotel as a recommended combo
chosen_flight = flights[0]
chosen_hotel = hotels[0]
final_answer = (f"Recommended trip:\nFlight: {chosen_flight['summary']} at {chosen_flight['price']}\n"
f"Hotel: {chosen_hotel['name']} at {chosen_hotel['price_per_night']} per night.")
else:
final_answer = "Sorry, I could not find a complete trip option."
# Output final answer back to user (this would be returned by the agent in a chat, etc.)
print("Travel Planner Agent to User:", final_answer)
In this pseudo-code, A2AClient is an imagined helper class (the actual implementation in the samples might be slightly different, but conceptually similar). The Travel Planner creates tasks for each remote agent and sends them. The streaming responses are handled in the loop where we print updates; in a real app, you might accumulate them or update a UI in real-time. Finally, when both tasks complete, we combine the results. The important thing to note is that all communication between the Travel Planner and the specialist agents is done via A2A protocol calls – we didn’t have to worry about how the Flight Finder is implemented or how the Hotel Finder works internally; we just treat them as services with an A2A interface.
This travel booking example is analogous to many real-world multi-agent workflows. In fact, Google’s blog describes a similar orchestration in the context of hiring: a hiring manager’s agent coordinates with other agents that specialize in candidate sourcing, interview scheduling, and background checks. Whether it’s travel booking, order fulfillment, or incident response, A2A provides the glue that lets specialized AI agents cooperate to handle the end-to-end process.
By using A2A, our Travel Planner agent avoided hard-coding any flight or hotel logic. It could swap out the Flight Finder agent for a different one (say, from another provider) just by pointing to a different Agent Card URL, without code changes – as long as that agent adheres to the A2A protocol. This demonstrates the powerful modularity and interoperability that A2A brings.
Final Thoughts
Google’s Agent2Agent Protocol (A2A) represents a significant step toward open, interoperable AI ecosystems. By allowing agents to communicate through a standardized protocol, A2A frees developers from the tedium of one-off integrations and enables organizations to mix-and-match the best AI components for each task. The protocol’s emphasis on using existing web standards, being secure and extensible, and handling complex interactive tasks makes it a practical choice for real-world deployments. We can envision a future where an organization’s various AI agents – whether developed in-house or provided by different vendors – can seamlessly form “agent teams” to tackle problems, much like microservices today cooperate in software architecture. This could lead to unprecedented levels of automation and efficiency, as hinted by the early partner experiments in areas like enterprise workflows and customer service.
It’s important to note that A2A is still evolving. The current release is a draft/prototype, with plans for a production-ready version later in the year. The community around A2A is rapidly growing: over four thousand developers have starred the GitHub project, and many are contributing ideas and feedback. Google has outlined “what’s next” for A2A, including improvements in agent discovery, richer skill querying, better UX negotiation (imagine agents figuring out on the fly if they should switch from text to a video call), and more robust streaming and notification features. They also plan to add more samples and documentation – for example, simpler quick-start examples and integration with additional agent frameworks. This open development process means your voice can be part of shaping A2A’s future.
If you’re excited about A2A, a great next step is to explore the official resources. Check out the A2A GitHub repository which contains the code, samples, and a link to technical documentation. The repo’s README provides a high-level overview and links to key topics like how A2A dovetails with MCP, how to handle enterprise requirements, etc. You can also join the discussion via the GitHub Discussions page to ask questions or share use cases. If you encounter issues or have suggestions, the project welcomes community feedback and contributions (see the Contributing guide in the repo). By contributing or even just experimenting and providing feedback, you become part of the effort to refine this protocol.
In conclusion, A2A has the potential to be the “lingua franca” for AI agents, much like HTTP is for web services. It’s an important development for anyone interested in multi-agent systems, AI interoperability, or building complex AI-driven applications. With A2A, we no longer have to build mega-agents that try to do everything; we can build small, expert agents and trust that they can work together when needed. The end result is a more flexible, powerful AI architecture that can adapt as new capabilities emerge. As the A2A project is open source under an Apache 2.0 license and driven in the open, it invites all of us to collaborate in unlocking this future. We encourage you to dive into the A2A samples, try creating an agent or two, and imagine the possibilities of this new era of agent interoperability!
Tega AdeyemiApril 11, 2025