
In a world overflowing with data, finding the right document feels like searching for a needle in a haystack. The "AI Document Navigator" changes that. It uses cutting-edge AI to make the process simple. This blog dives into how it leverages OpenAI's GPT-4-o to help users pinpoint relevant documents with ease.
Key Features of the AI Document Navigator
- Natural Language Processing: This tool understands natural language queries, allowing users to search for documents as easily as asking a question.
- Document Retrieval and Summarization: It retrieves document names, provides summaries, and explains why these documents are relevant to the query, making it easier for users to decide which documents to delve into.
- User-Friendly Interface: Built with Streamlit, the interface is straightforward, featuring options that guide users through document retrieval without any hassle.
Tools and Technologies Used
- LLM (Large Language Model): Uses OpenAI's GPT-3.5, known for its advanced language understanding capabilities. This LLM handles the complex task of generating summaries of documents, interpreting user queries and generating contextually relevant responses.
- Document Processing: Utilizes PyPDF2 for handling PDF documents, which is essential for extracting text that can be processed and indexed by the system.
- LlamaIndex: A robust framework that facilitates interaction with the language model and manages document data efficiently. It plays a crucial role in creating and querying document summary and indexes.
- Streamlit: It simplifies the UI creation and provides an intuitive interface for improving user experience.
Why Use LlamaIndex?
LlamaIndex was chosen for its robust features in managing language models and document data efficiently, making it an excellent fit for this project compared to other tools which might offer similar functionalities but with less emphasis on integration and ease of use.
The application flow begins with the creation of a vector index from documents using the DocumentSummaryIndex. This process not only indexes the documents but also creates summaries of them. These summaries are stored alongside the vectors in the index, facilitating efficient retrieval. This dual capability of indexing and summarizing documents significantly enhances the retrieval process, allowing for more context-aware and relevant search results.
One of the key components of LlamaIndex that makes it particularly valuable for the "AI Document Navigator" is the "DocumentSummaryIndexLLMRetriever." This module utilizes Large Language Models (LLMs) to interpret queries and select the most relevant document summaries from an index. It sends queries and summary nodes to the LLM, which then identifies the most pertinent summaries based on its understanding of the query's context and content.
Deep Dive into the Code
Loading and Processing Documents:
This function reads PDFs from a directory, extracts text from each page, and saves it as a text file. This is crucial for making the text searchable by the AI.
def process_pdf_documents():
pdf_directory = Path("pdfs")
for pdf_file in pdf_directory.glob("*.pdf"):
with open(pdf_file, "rb") as file:
reader = PyPDF2.PdfReader(file)
text = [page.extract_text() for page in reader.pages if page.extract_text()]
output_file_path = Path("txt") / f"{pdf_file.stem}.txt"
with open(output_file_path, "w", encoding="utf-8") as output_file:
output_file.write("\n".join(text))Building and Using the Document Summary Index:
This snippet sets up a document summary index, which creates document summaries while creating indexes. It is essential for quickly retrieving document summaries and facilitating efficient search capabilities.
def build_document_summary_index(docs):
# Initialize the SentenceSplitter for splitting long sentences
splitter = SentenceSplitter(chunk_size=1024)
# Setup the response synthesizer with the specified mode
response_synthesizer = get_response_synthesizer(
response_mode="tree_summarize", use_async=True
)
# Build the document summary index
doc_summary_index = DocumentSummaryIndex.from_documents(
docs,
llm=llm,
transformations=[splitter],
response_synthesizer=response_synthesizer,
show_progress=True,
)
return doc_summary_indexHandling User Queries and Generating Responses:
This part of the code captures user input, retrieves relevant document information based on the query, generates a justification for document selection and displays the final response to the user, making it a core functionality of the navigator.
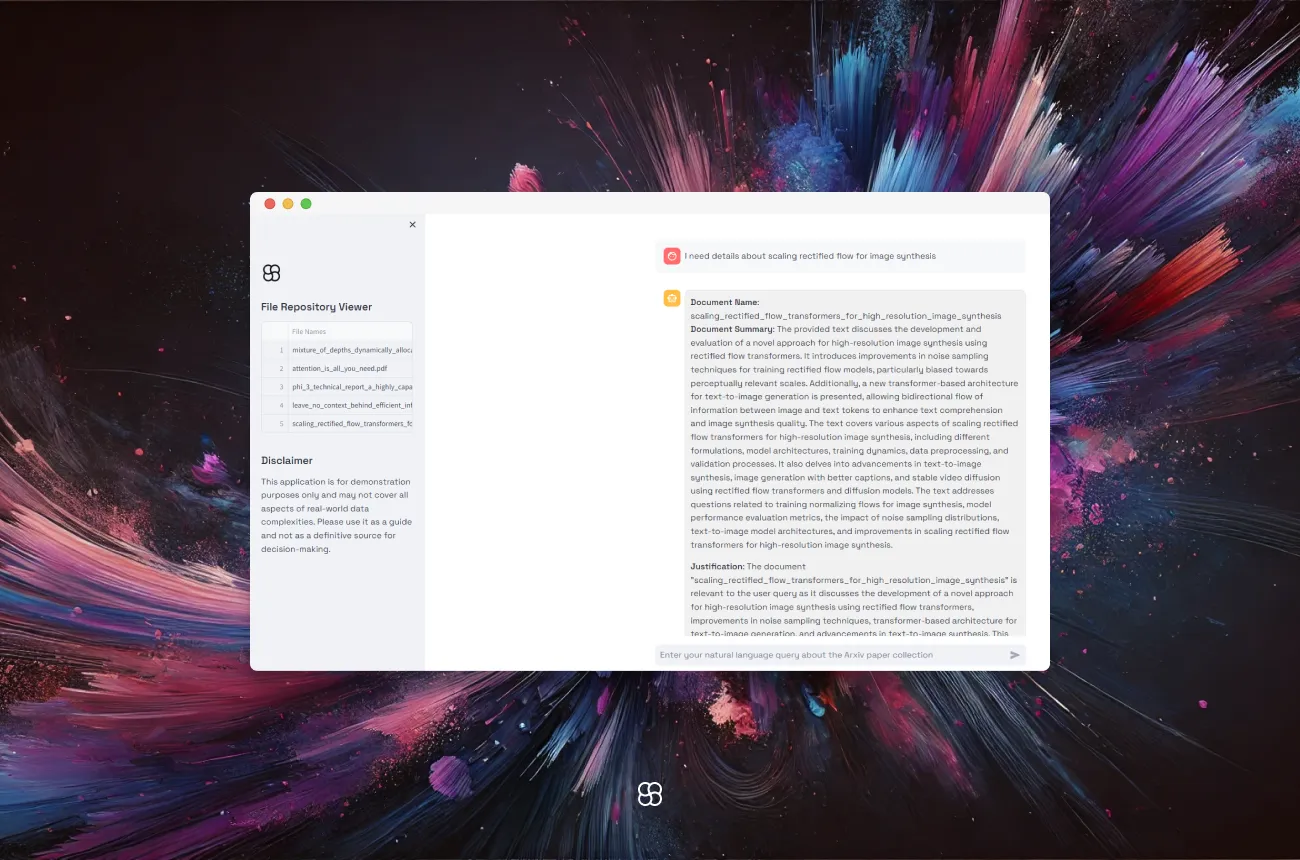
When a user submits a query through the interface, the code retrieves relevant documents using a custom retriever object. For each retrieved document, it extracts the document name and summary, checks for duplicates, and stores them in a dictionary. If the document is new, it uses an AI model to generate a justification for the document's relevance to the query. Each document's details and the AI-generated justification are formatted and displayed in the app. All user queries and AI responses are stored in the session history for continuous interaction.
prompt = st.chat_input("Enter your natural language query about the Arxiv paper collection")
if prompt:
with st.spinner():
add_to_message_history("user", prompt)
with st.chat_message("user"):
st.write(prompt)
with st.chat_message("assistant"):
retrieved_nodes = retriever.retrieve(prompt)
doc_summary_by_name = {}
for node in retrieved_nodes:
doc_name = node.metadata['file_name']
doc_summary = f"{doc_summary_index.get_document_summary(node.node.ref_doc_id)}"
if doc_name not in doc_summary_by_name:
doc_summary_by_name[doc_name] = doc_summary
responses = []
for doc_name, summaries in doc_summary_by_name.items():
text = f"""
**Document Name**: {os.path.splitext(doc_name)[0]}
**Document Summary**: {summaries}"""
llmresponse = llm.complete(f"""
User asked a query, for which our AI application has suggested a document which contains relevant information for the user query. The document's name and summary is provided below in card markdown:
card markdown: {text}
Based on the above information, provide a justification as to why the above document is relevant to the user query. Return just the justification text and nothing else.
""")
finalresponse = f"{text.rstrip()} \n\n**Justification**: {llmresponse.text}"
responses.append(finalresponse)
st.markdown(f"""
<div style="background-color: #f1f1f1; padding: 10px; border-radius: 10px; border: 1px solid #e1e1e1;">
{finalresponse}
</div>
""", unsafe_allow_html=True)
combinedfinalresponse = "\n\n---\n\n".join(responses)
add_to_message_history("assistant", combinedfinalresponse)Enhancing User Experience
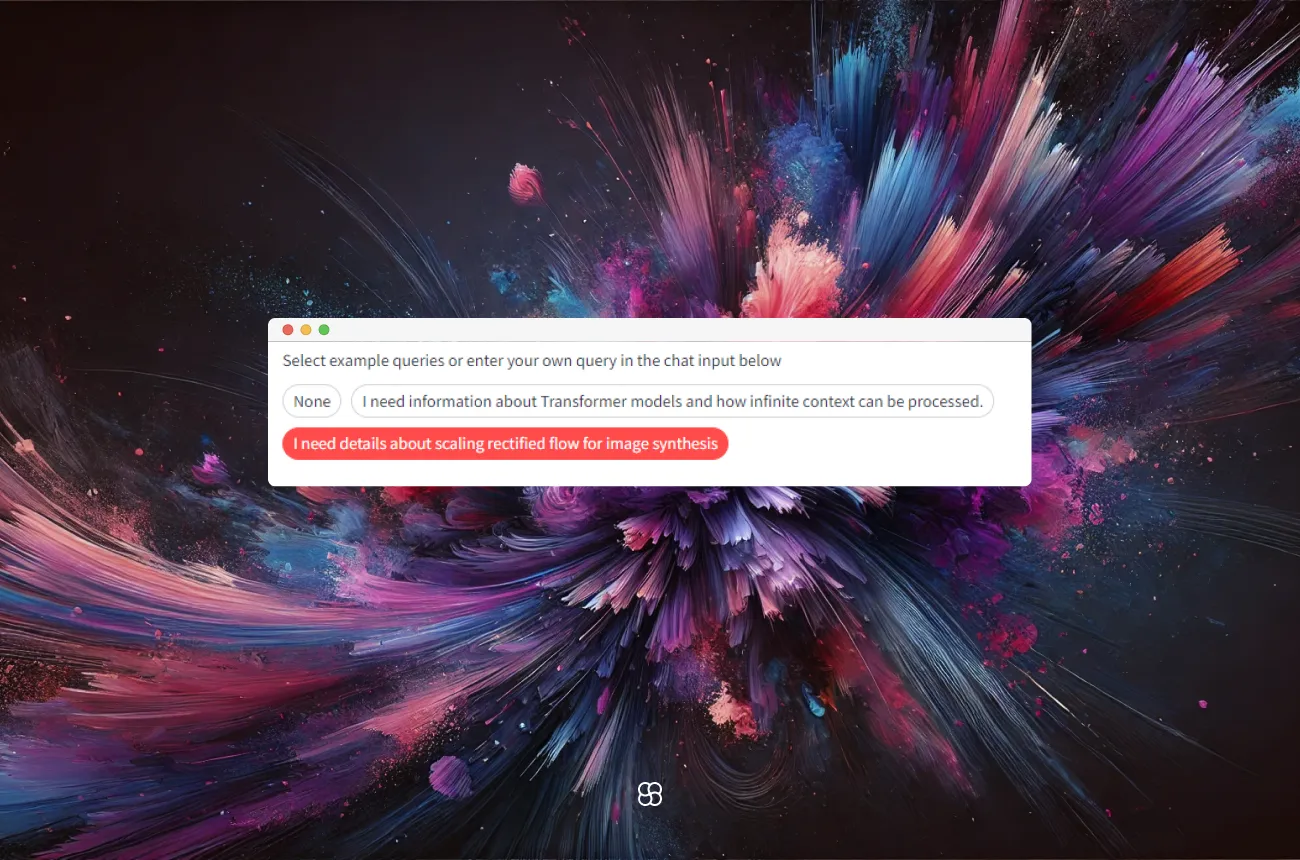
Streamlit Pills
Streamlit pills offer a simple way for users to select pre-defined or custom queries, enhancing the interface's interactivity and user-friendliness. By integrating these, the application allows for effortless navigation through the document search process.
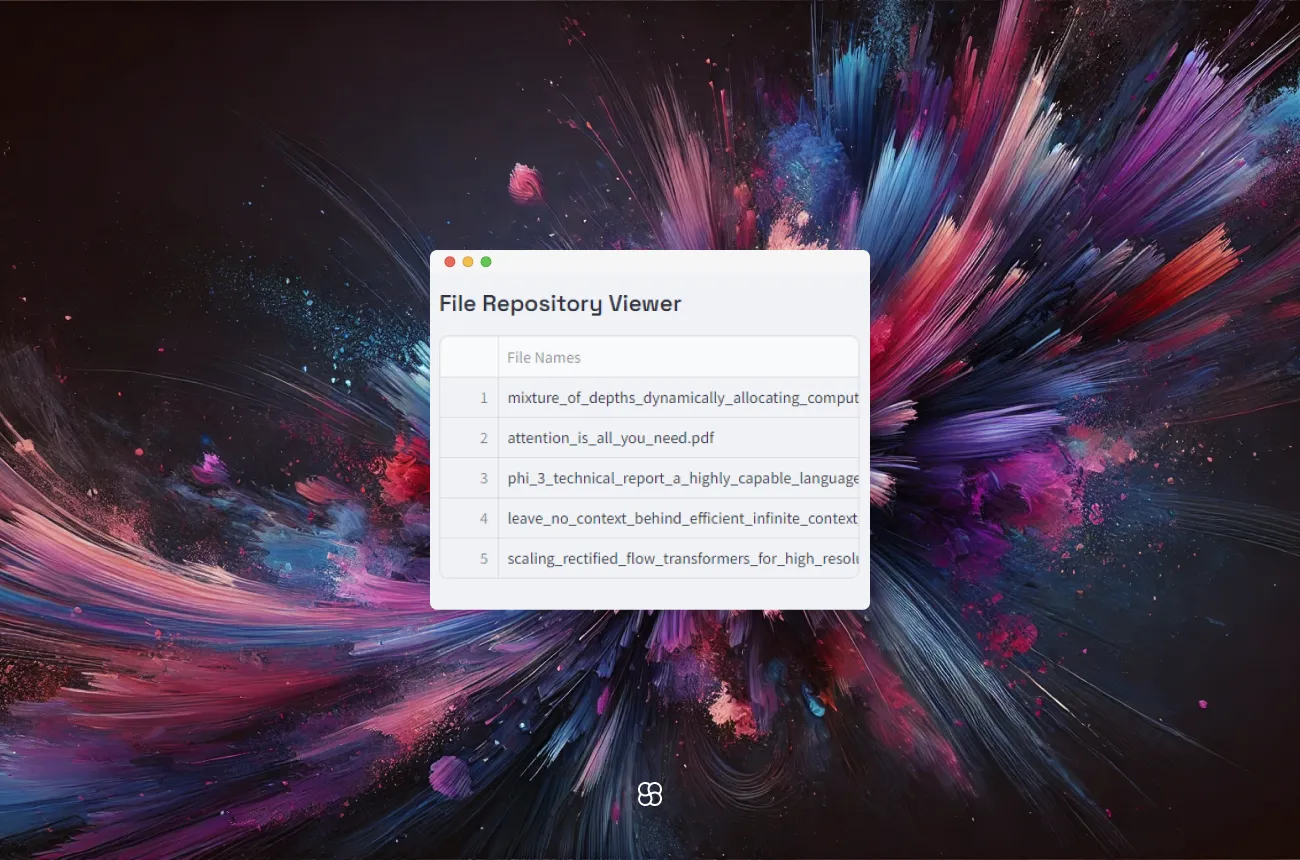
Document Viewer
The document viewer in the sidebar on the left allows users to see the files that are currently part of the repository.
Conclusion
The "AI Document Navigator" uses LLMs and RAG to change how we find and use information in large document collections. This tool simplifies searching and understanding documents with its easy-to-use design and powerful technology. By diving into its code and features, we see a great mix of simple front-end design and complex back-end operations. As a prototype, it shows how such tools could help businesses manage their overwhelming amounts of documents, making information retrieval quicker and more effective.
Author
