
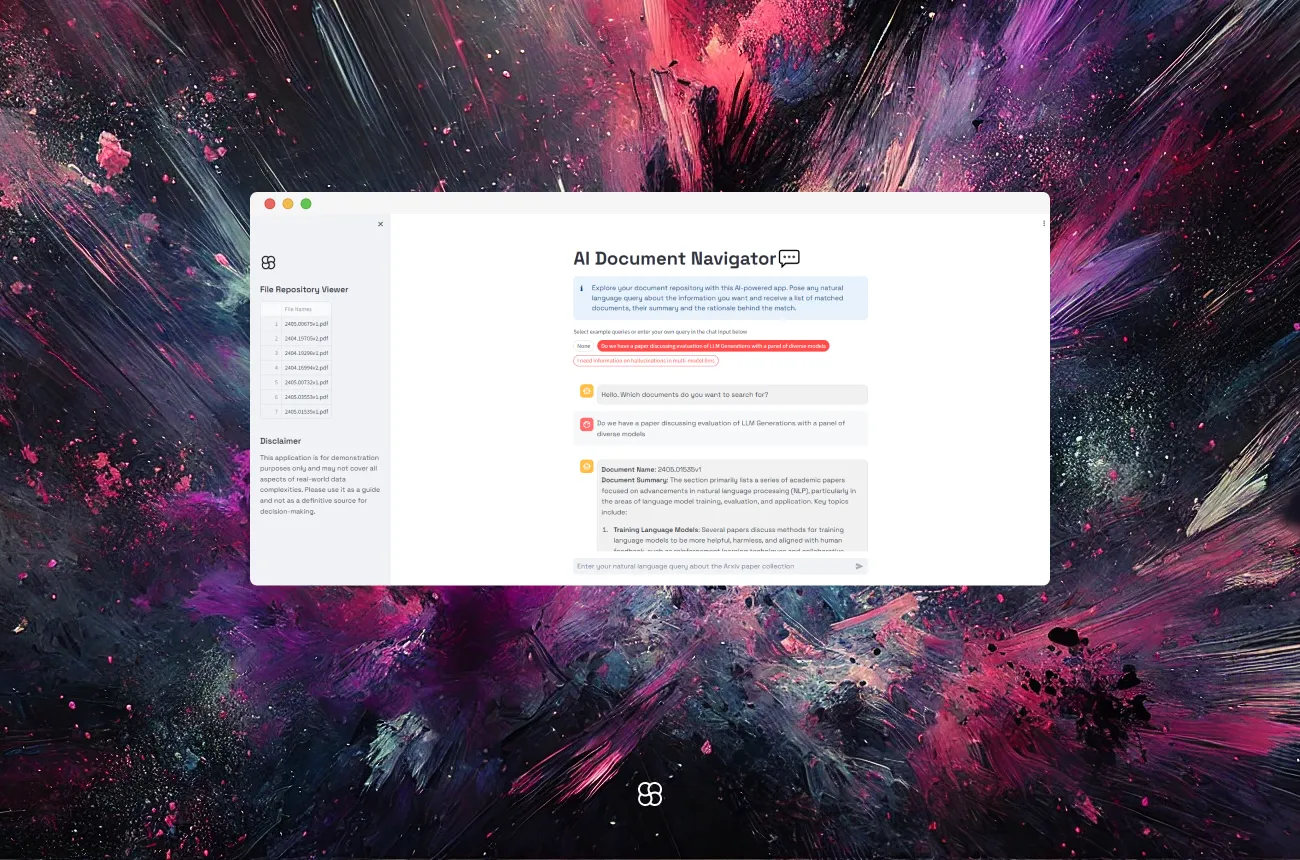
Finding the right document in a flood of data is overwhelming. The "AI Document Navigator" was built to solve this, using cutting-edge AI to quickly locate documents based on user queries. This blog article dives into the tool’s evolution. Part 1 focused on retrieving documents through summaries. Part 2 takes it further—combining enriched metadata with summaries and chunk-based retrieval.
By incorporating metadata generated by LLMs, such as keywords, key topics, and document creation dates, this enhanced version offers more precise and contextually relevant document retrieval. Additionally, users can now filter documents by including specific dates in the MM/YYYY format in their queries, making the search process even more efficient and tailored to their needs.
Key Features of the Enhanced AI Document Navigator
1. Advanced Metadata Handling: Unlike the initial version, which primarily focused on document retrieval based on normal chunks and summaries, this enhanced tool now leverages metadata generated using LLMs. It generates keywords, identifies key topics, and enriches the metadata with the document's creation date and other relevant information.
2. Date-Based Filtering: Users can include dates in the MM/YYYY format in their queries. The application intelligently filters the results to show only papers written in the specified month and year.
3. Improved Document Retrieval and Summarization: By combining enriched metadata, summaries, and normal chunking-based retrieval, the tool retrieves document names, provides summaries, and explains why these documents are relevant to the query. This enhancement results in finer and more accurate responses, making it easier for users to decide which documents to delve into.
4. User-Friendly Interface: Built with Streamlit, the interface remains straightforward, featuring options that guide users through document retrieval without hassle. The streamlined design ensures an intuitive experience, enhancing user interaction and satisfaction.
Tools and Technologies Used
- LLM (Large Language Model): Utilizes OpenAI's GPT-3.5 for advanced language understanding, summarization, and response generation.
- Document Processing: Uses PyPDF2 for handling PDF documents, essential for extracting text for processing and indexing.
- LlamaIndex: A robust framework facilitating interaction with the language model and managing document data efficiently.
- Streamlit: Simplifies UI creation and provides an intuitive interface for improving user experience.
Enhanced Features and Benefits
1. Advanced Metadata Extraction:The updated version, in addition to document summaries, also adds metadata such as important entities, creation dates, and keywords to each document chunk during ingestion. This metadata aids in more precise document retrieval and relevance determination.
2. Date-Based Query Filtering:Users can include dates in the format 'MM/YYYY' in their queries to filter documents by creation date. This feature enhances the relevance of search results. Similar filter can be extended for any of the metadata fields.
Deep Dive into the Enhanced Code
Loading and Processing Documents:
This function reads PDFs from a directory, extracts text from each page, and saves it as a text file, crucial for making the text searchable by the AI.
def process_pdf_documents():
data_path = Path("txt")
data_path.mkdir(exist_ok=True)
pdf_directory = Path("pdfs")
for pdf_file in pdf_directory.glob("*.pdf"):
with open(pdf_file, "rb") as file:
reader = PyPDF2.PdfReader(file)
text = [page.extract_text() for page in reader.pages if page.extract_text()]
output_file_path = data_path / f"{pdf_file.stem}.txt"
with open(output_file_path, "w", encoding="utf-8") as output_file:
output_file.write("\n".join(text))
arxiv_docs = []
for text_file in data_path.glob("*.txt"):
docs = SimpleDirectoryReader(input_files=[str(text_file)]).load_data()
docs[0].doc_id = text_file.stem
arxiv_docs.extend(docs)
return arxiv_docsBuilding the Enhanced Document Index:
This snippet sets up a document index, creating document summaries while creating indexes. It is essential for quickly retrieving document summaries and facilitating efficient search capabilities. We use SummaryExtractor to extract document summaries. Further, we use QuestionsAnsweredExtractor and KeywordExtractor to extractor relevant keywords and sample Q&A pairs to enrich the metadata.
def build_document_summary_index(docs):
node_parser = TokenTextSplitter(separator=" ", chunk_size=2048, chunk_overlap=200)
orig_nodes = node_parser.get_nodes_from_documents(arxiv_documents)
extractors_2 = [
SummaryExtractor(summaries=["prev", "self", "next"], llm=llm),
QuestionsAnsweredExtractor(questions=3, llm=llm, metadata_mode=MetadataMode.EMBED),
KeywordExtractor(keywords=10, llm=llm),
]
pipeline = IngestionPipeline(transformations=[node_parser, *extractors_2])
nodes_2 = pipeline.run(nodes=orig_nodes, in_place=False, show_progress=True)
index = VectorStoreIndex(nodes_2)
return indexHandling User Queries and Generating Responses:
Captures user input, retrieves relevant document information based on the query, generates a justification for document selection, and displays the final response to the user.
import re
prompt = st.chat_input("Enter your natural language query about the Arxiv paper collection")
if prompt:
with st.spinner():
add_to_message_history("user", prompt)
with st.chat_message("user"):
st.write(prompt)
with st.chat_message("assistant"):
retrieved_nodes = retriever.retrieve(prompt)
date_pattern = r'\b\d{2}/\d{4}\b'
match = re.search(date_pattern, prompt)
if match:
extracted_date = match.group(0)
print(f"Extracted date: {extracted_date}")
filtered_nodes = [node for node in retrieved_nodes if node.metadata['creation_date'] == extracted_date]
else:
print("No date found in the prompt.")
filtered_nodes = retrieved_nodes
doc_summary_by_name = {}
doc_keywords_by_name = {}
for node in filtered_nodes:
doc_name = node.metadata['file_name']
doc_keywords = node.metadata['excerpt_keywords']
doc_summary = node.metadata['section_summary']
if doc_name in doc_summary_by_name:
doc_summary_by_name[doc_name] += doc_summary
doc_keywords_by_name[doc_name] += doc_keywords
else:
doc_summary_by_name[doc_name] = doc_summary
doc_keywords_by_name[doc_name] = doc_keywords
responses = []
for doc_name, summaries in doc_summary_by_name.items():
text = f"""
**Document Name**: {os.path.splitext(doc_name)[0]}
**Document Summary**: {summaries} \n
**Document Keywords**: {doc_keywords_by_name[doc_name]}"""
llmresponse = llm.complete(f"""
User asked a query, for which our AI application has suggested a document which contains relevant information for the user query. The document's name, summary and keywords are provided below in card markdown:
User query: {prompt}
card markdown: {text}
Based on the above information, first check if the document is relevant to the user query. Only if it is absolutely relevant, then provide a justification as to why the above document is relevant to the user query. Otherwise reply saying that document is irrelevant
""")
finalresponse = f"{text.rstrip()} \n\n**Justification**: {llmresponse.text}"
responses.append(finalresponse)
st.markdown(f"""
<div style="background-color: #f1f1f1; padding: 10px; border-radius: 10px; border: 1px solid #e1e1e1;">
{finalresponse}
</div>
""", unsafe_allow_html=True)
combinedfinalresponse = "\n\n---\n\n".join(responses)
add_to_message_history("assistant", combinedfinalresponse)
Enhancing User Experience
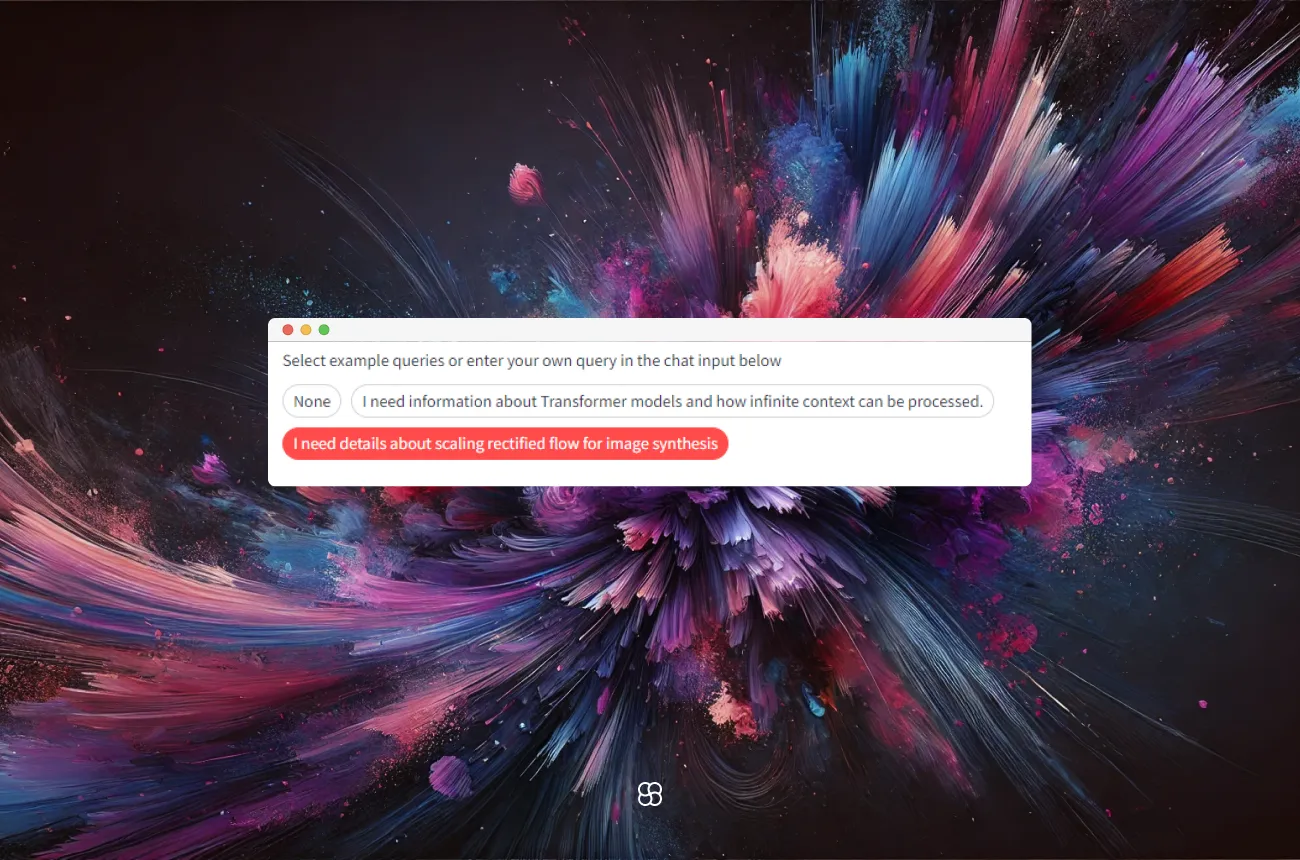
Streamlit Pills:
Streamlit pills offer a simple way for users to select predefined or custom queries, enhancing the interface's interactivity and user-friendliness. By integrating these, the application allows for effortless navigation through the document search process.
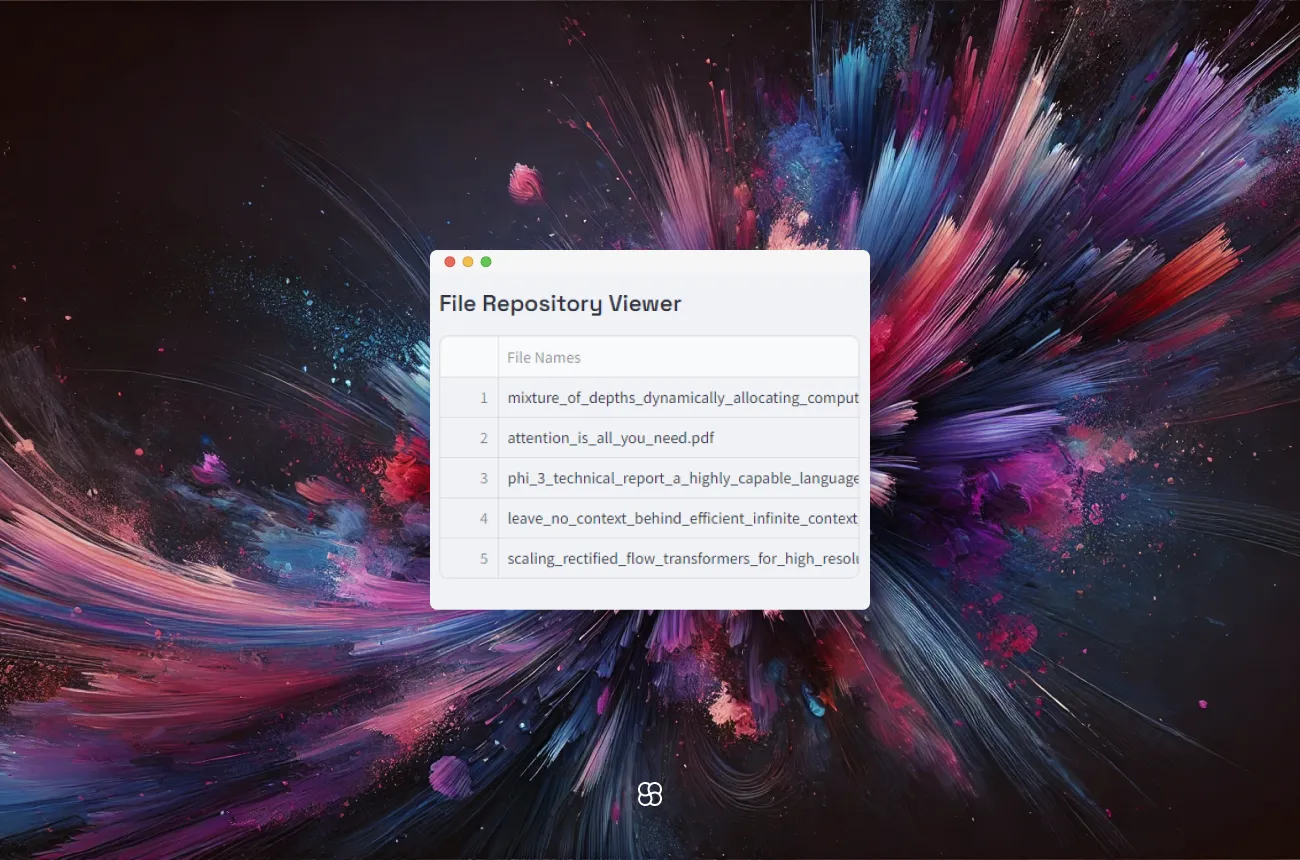
Document Viewer:
The document viewer in the sidebar on the left allows users to see the files that are currently part of the repository.
Conclusion
The enhanced "AI Document Navigator" leverages LLMs and advanced metadata to revolutionize how we find and use information in large document collections. This tool simplifies searching and understanding documents with its easy-to-use design and powerful technology. By diving into its code and features, we see a great mix of simple front-end design and complex back-end operations. As a prototype, it shows how such tools could help businesses manage their overwhelming amounts of documents, making information retrieval quicker and more effective.
Author
