
Indexing datasets is an essential step for efficient and advanced data retrieval, especially when working with Large Language Models (LLMs). LlamaIndex is a cutting-edge framework designed to bridge your data with LLMs, enabling sophisticated querying capabilities. This guide provides a detailed, step-by-step walkthrough for indexing your dataset with LlamaIndex, including code snippets and actionable insights.
What is LlamaIndex?
LlamaIndex is an open-source data orchestration framework tailored for building applications powered by LLMs. It simplifies the process of connecting domain-specific datasets to language models, streamlining data ingestion, indexing, and querying. By creating structured indices over datasets, LlamaIndex enhances LLMs’ ability to retrieve relevant information and handle complex queries effectively.
Key benefits
- Advanced Retrieval Strategies: LlamaIndex supports a variety of advanced retrieval methods, including semantic search, summarization, and multi-document queries. These techniques allow for more precise and relevant data retrieval, tailored to the specific needs of the query.
- Integration with LLMs: The platform's seamless integration with various LLMs, including custom models, enables it to provide contextually relevant responses that are both accurate and informative.
- Data Privacy and Security: LlamaIndex offers robust options for data privacy and security, allowing users to choose where and how their data is processed and stored.
Getting Started
Installation and Setup
1. Install LlamaIndex:
Ensure you have Python installed on your system. You can install LlamaIndex using pip:
pip install llama-index2. Set Up OpenAI API Key:
LlamaIndex utilizes OpenAI's language models for certain operations. Obtain an API key from OpenAI and set it as an environment variable:
export OPENAI_API_KEY='your_openai_api_key'First Steps
Step 1: Import Necessary Libraries
Start by importing the required modules:
from llama_index import SimpleDirectoryReader, VectorStoreIndexStep 2: Load Your Dataset
Assume your dataset is stored in a directory named data/. Load the documents as follows:
# Load documents from the 'data' directory
documents = SimpleDirectoryReader('data').load_data()Step 3: Create the Index
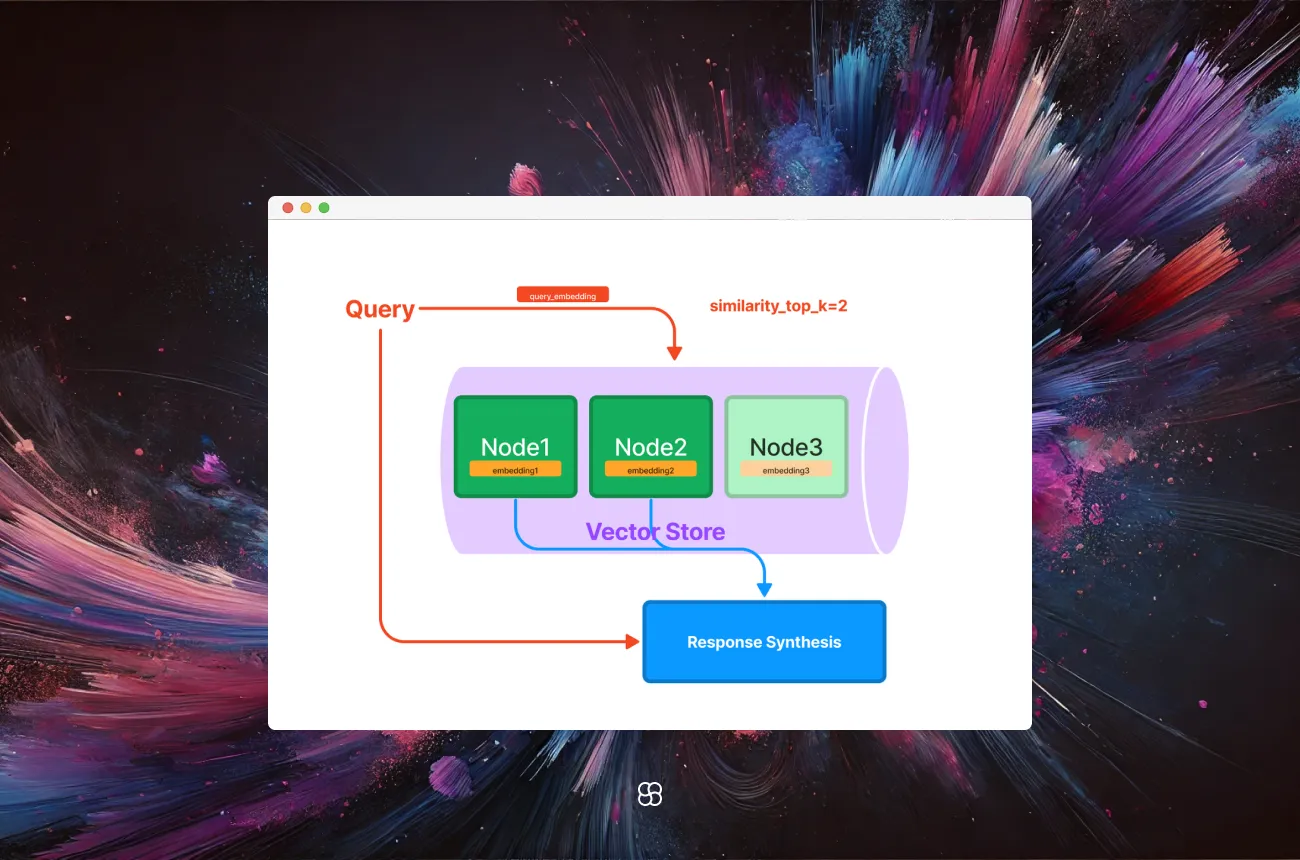
Once the dataset is loaded, create a vector store index to structure and organize the data for querying:
index = VectorStoreIndex.from_documents(documents)First Run
After setting up the index, you can perform queries to retrieve information:
query_engine = index.as_query_engine()
response = query_engine.query("Your query here")
print(response)This will output the response generated based on the indexed data, allowing you to interact with your dataset using natural language queries.
Step-by-Step Example: Building a Simple Retrieval Agent
Let's build a simple retrieval agent that indexes a dataset and allows for advanced querying using LlamaIndex.
1. Set Up the Environment:
Ensure that LlamaIndex is installed and your OpenAI API key is configured as described in the installation steps.
2. Prepare Your Dataset:
Organize your dataset in a directory (e.g., 'data/') with each document as a separate text file.
3. Load and Index the Dataset:
Use the following code to load and index your dataset:
from llama_index import SimpleDirectoryReader, VectorStoreIndex
# Load documents from the 'data' directory
documents = SimpleDirectoryReader('data').load_data()
# Create a vector store index from the documents
index = VectorStoreIndex.from_documents(documents)4. Create a Query Engine:
Initialize a query engine to interact with the index:
query_engine = index.as_query_engine()5. Perform Queries:
You can now perform queries to retrieve information from your dataset:
# Example query
response = query_engine.query("What are the main topics covered in the dataset?")
print(response)This setup allows you to interact with your dataset using natural language queries, leveraging the indexing capabilities of LlamaIndex for advanced retrieval.
Why Use LlamaIndex?
LlamaIndex enhances LLM-based applications with advanced data retrieval capabilities. Here’s why it stands out:
- Efficiency: Quickly processes and indexes large datasets, ensuring faster query responses.
- Flexibility: Supports various data formats and retrieval strategies tailored to your use case.
- Scalability: Handles increasing dataset sizes and query complexity with ease.
Final Thoughts
LlamaIndex is a robust tool for creating efficient indices over datasets, enabling LLMs to perform sophisticated retrieval tasks. Whether you’re working with text files, web content, or proprietary data, LlamaIndex simplifies data orchestration, enhancing how you query and interact with information.
By following this guide, you’re equipped to:
- Index your datasets efficiently.
- Perform advanced natural language queries.
- Build powerful retrieval agents tailored to your specific needs.
Further Exploration
For advanced use cases, explore:
Start transforming your data retrieval workflows today with LlamaIndex!
Tega AdeyemiJanuary 21, 2025