
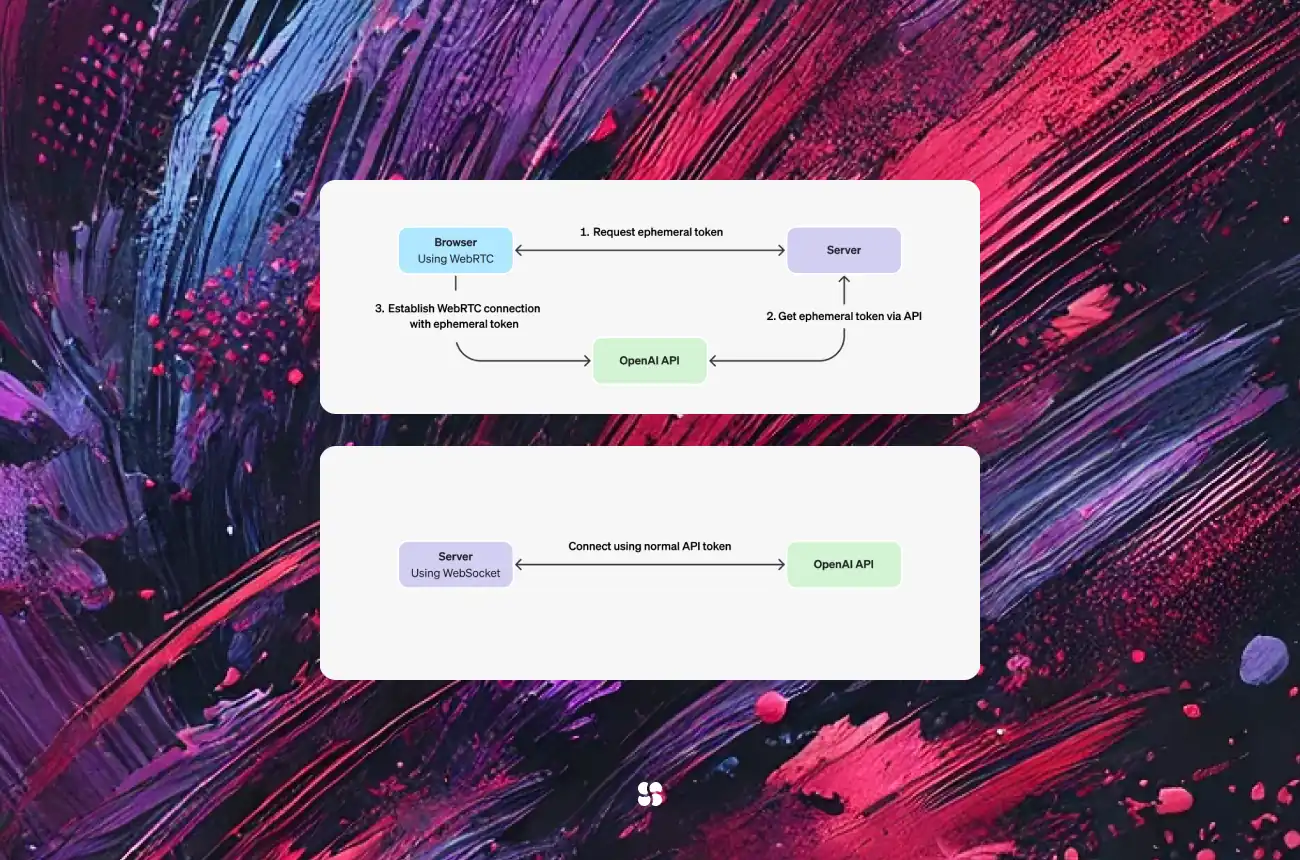
The OpenAI Real-Time Speech API is designed to process live audio streams, transcribing spoken language into text almost instantaneously. By leveraging robust, scalable cloud infrastructure and advanced language models, the API empowers developers to integrate real-time voice capabilities into a wide range of applications—from interactive voice assistants and live captioning systems to customer service bots. The framework is built for low latency and high reliability, making it an ideal solution for time-sensitive applications.
Voice agents make agent failures audible — designing the guardrails that keep them safe in production is the subject of Cohorte's Building Accountable AI Agents course (E3).
Benefits of Using the Real-Time Speech API
- Instantaneous Transcription: Capture and process speech in near real time, enabling dynamic, responsive user experiences.
- Scalability: Handle multiple streams concurrently, making it suitable for both small applications and large-scale deployments.
- Developer-Friendly: Clear documentation and straightforward API endpoints simplify integration and customization.
- Versatility: Easily combine with other OpenAI models to create sophisticated, multi-modal applications.
Getting Started
1. Installation and Setup
To begin using the Real-Time Speech API, ensure you have the necessary Python packages installed. You will typically need:
- OpenAI Python SDK: For interfacing with OpenAI services.
- Websockets library: For handling real-time data streams.
Install the required packages using pip:
pip install openai websocketsNext, set your OpenAI API key as an environment variable or include it directly in your code (ensure you follow best practices for security). For example:
import os
os.environ["OPENAI_API_KEY"] = "YOUR_API_KEY"2. First Steps & Initial Run
A simple “hello world” for the API involves establishing a websocket connection and sending a configuration message. Here’s a snippet to help you get started:
import asyncio
import json
import websockets
import os
async def initiate_realtime_session():
uri = "wss://api.openai.com/v1/realtime"
headers = {"Authorization": f"Bearer {os.environ.get('OPENAI_API_KEY')}"}
async with websockets.connect(uri, extra_headers=headers) as websocket:
# Send configuration message to start session
start_message = json.dumps({
"type": "start",
"language": "en-US",
"sample_rate": 16000 # Example parameter
})
await websocket.send(start_message)
print("Session started, waiting for responses...")
# Await and print the first response (this would normally be continuous)
response = await websocket.recv()
print("Response from API:", response)
# Run the async session starter
asyncio.run(initiate_realtime_session())This snippet establishes a secure websocket connection to the API, sends a configuration message to initiate the session, and prints the first response received.
Step-by-Step Example: Building a Simple Voice Agent
Let’s build a basic agent that continuously captures audio from your microphone and sends audio chunks to the Real-Time Speech API. In a real-world scenario, you might use a library like PyAudio for audio capture. The following example uses a placeholder function (get_audio_chunk()) to simulate capturing audio data.
Example Code:
import asyncio
import json
import websockets
import os
# Placeholder function to simulate audio capture.
# Replace with actual audio capture code (e.g., using PyAudio)
def get_audio_chunk():
# In a real implementation, capture a small audio frame (bytes) from your microphone.
# Here we simply return None to indicate no more data.
return None
async def realtime_speech_agent():
uri = "wss://api.openai.com/v1/realtime"
headers = {"Authorization": f"Bearer {os.environ.get('OPENAI_API_KEY')}"}
async with websockets.connect(uri, extra_headers=headers) as websocket:
# Begin the session by sending initial configuration
config = json.dumps({
"type": "start",
"language": "en-US",
"sample_rate": 16000
})
await websocket.send(config)
print("Real-time session initiated.")
# Main loop: send audio chunks and process responses
while True:
audio_chunk = get_audio_chunk() # Replace with actual audio capture
if audio_chunk is None:
break # End of audio stream
await websocket.send(audio_chunk)
# Non-blocking receipt of API responses
try:
response = await asyncio.wait_for(websocket.recv(), timeout=1.0)
parsed_response = json.loads(response)
# Assuming the API sends transcription text under the key 'text'
if 'text' in parsed_response:
print("Transcription:", parsed_response['text'])
except asyncio.TimeoutError:
# No response received within timeout window; continue sending audio.
continue
# Optionally, signal the end of the stream if the API requires it.
end_message = json.dumps({"type": "stop"})
await websocket.send(end_message)
print("Session ended.")
# Run the agent
asyncio.run(realtime_speech_agent())Explanation:
- Connection & Configuration:
The agent establishes a websocket connection using your API key, sending an initial configuration message that specifies the language and audio sample rate. - Audio Streaming Loop:
In the loop, audio data is captured (via the placeholderget_audio_chunk()) and transmitted to the API. The agent awaits responses that include transcription results and prints them to the console. - Handling Timeouts:
The code includes a timeout to ensure the agent continues running even if no immediate response is received, making it resilient to minor delays. - Session Termination:
When no more audio is available, a stop message is sent to properly close the session.
This example offers a blueprint for developing more complex applications by integrating live audio capture libraries and handling additional API message types as needed.
Final Thoughts
The OpenAI Real-Time Speech API offers a powerful toolkit for developers aiming to bring voice interaction to their applications. Its low latency, ease of integration, and versatility open the door to innovative use cases—from enhancing accessibility to building conversational agents. As you explore further:
- Experiment: Modify parameters, integrate with audio capture libraries, or combine with other OpenAI models to tailor the solution to your needs.
- Scale: Leverage the API’s scalability for both small prototypes and enterprise-grade applications.
- Iterate: Continuous testing and iteration will help refine performance, especially when dealing with live audio data.
By following the steps outlined above, you’ll be well on your way to creating a robust, real-time speech agent that harnesses the cutting-edge capabilities of OpenAI’s platform.
Tega AdeyemiApril 4, 2025