
“Why does my AI assistant sometimes answer instantly…and other times it spins like a slow pizza?” my friend asked.
“Because sometimes it’s ‘chatty.’ Other times it’s thinking,” I said.
“Thinking?”
“Yep. When it thinks, it rents a small supercomputer for a few seconds.”
“From where?”
“From the middle of a global tug-of-war over the fastest chips on Earth.”
He blinked. “Okay…start at the beginning.”
Let’s do exactly that.
The Headlines You’ve Seen (and What They Really Mean)
US restricts advanced Nvidia GPUs to China.
Translation: The US is trying to slow China from training and running the biggest, brainiest AI systems by limiting total compute that reaches Chinese labs and data centers.
China’s labs make surprising gains anyway (hello, DeepSeek).
Translation: With fewer “fancy” chips, Chinese engineers squeezed more from what they had—going ultra low-level and rewriting parts of the software stack so the hardware acts smarter than it looks on paper.
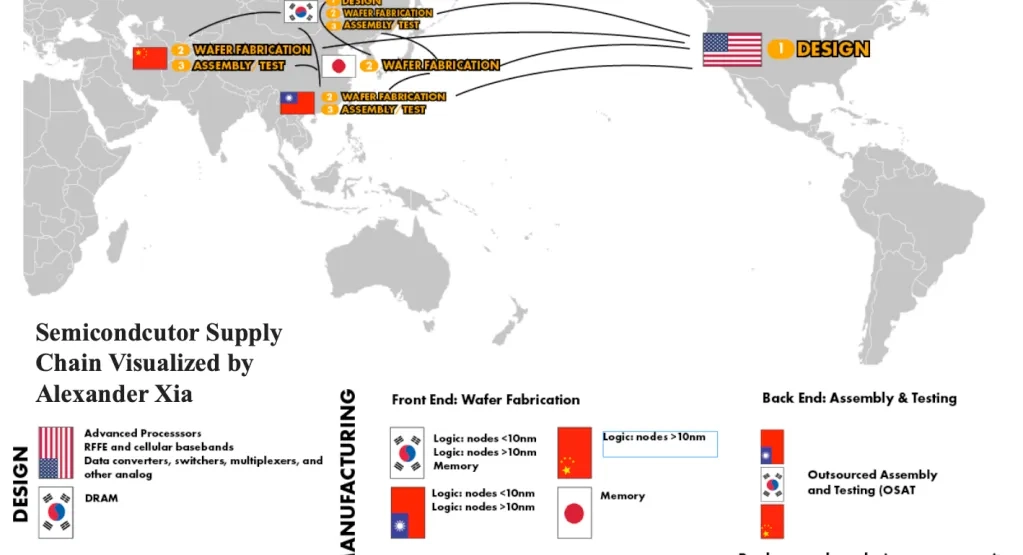
TSMC sits in the middle of everything.
Translation: One company in Taiwan manufactures the most advanced chips for basically everyone. That’s a supply-chain choke point—and a geopolitical headache.
Cloud loopholes and smuggling stories.
Translation: If you cap chip exports, people rent them through clouds abroad or… get creative with shipping routes. GPUs are small, pricey, and easy to move. Think diamonds, not dishwashers.
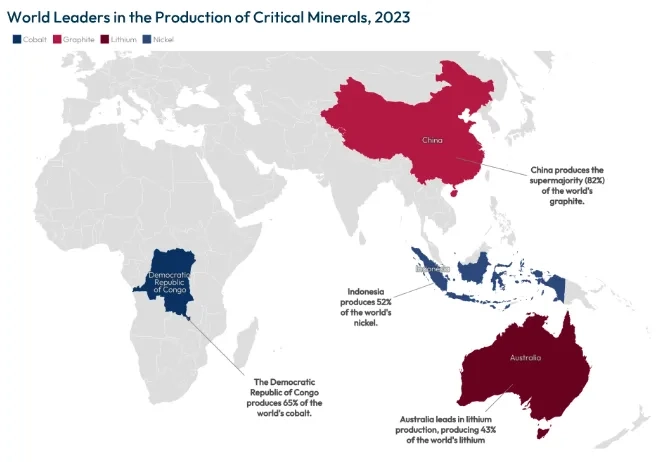
Chips are also about “critical minerals”, and when it comes to this, they are quite rare…
Wait—Why All This Now?
Because AI went from autocomplete to actual reasoning.
Older models were like fast typists: quick, cheap, good enough for short replies. Newer “reasoning models” (think OpenAI o1, DeepSeek-R1) do something different at inference time (aka when you ask a question):
- They think longer before answering.
- They run more compute after you hit enter, not just during the big, months-long training phase.
- A single hard question can cost $5–$20 in compute—1,000–10,000× a normal chat.
So if AI is going to plan trips, write code, prove theorems, and manage boring tasks for millions of people, we need a mountain of chips—not just to build the models, but to RUN them all day, every day.
That’s the fuel of this race.
The Hardware Moves (what changed on the chips)
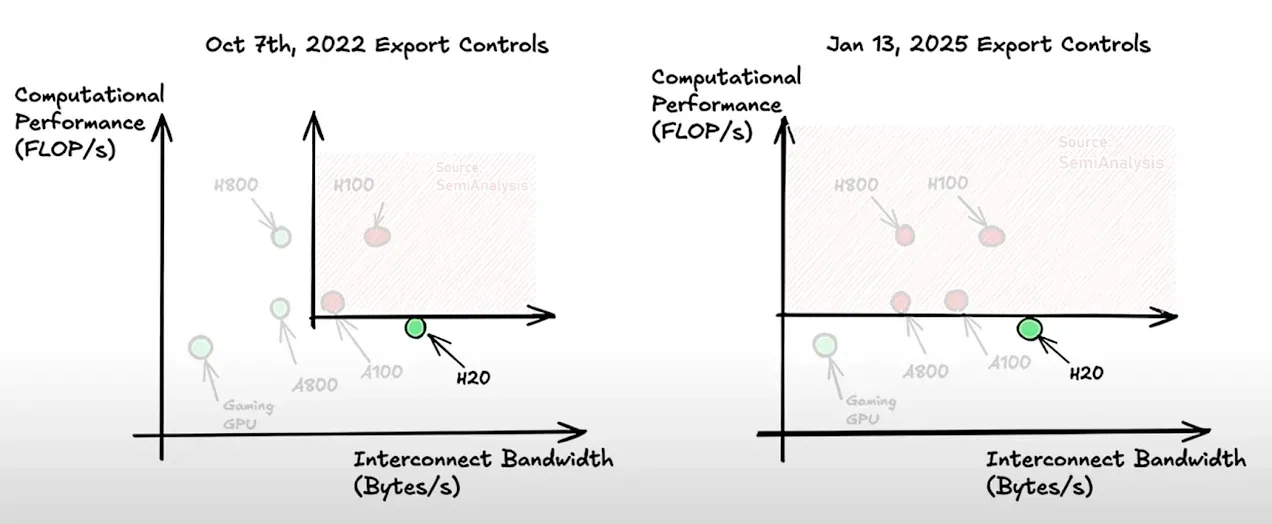
- Nvidia H100 (the all-star): Fast at math and fast at talking to its friends (great interconnect).
- H800 (the “China edition,” now banned): Same math muscles, but poor at group chat (interconnect throttled). Engineers had to hand-optimize how GPUs talk—like choreographing a dance manually.
- H20 (current allowed option): Less raw math (FLOPS) than H100—about one-third on paper—but similar interconnect and more memory. For long, think-y tasks that are memory hogs, H20 can shine despite the FLOPS haircut.
Key idea: For today’s reasoning AI, memory capacity and how fast chips talk can matter as much as raw “speed.” We’re not only bench-pressing; we’re running a library and a switchboard.
The Transformer in Your Pocket (Yes, You Use One)
Let’s demystify the buzzwords—attention, KV-cache, context window—using a regular conversation.
- Context window = how much the model can “keep in mind.”
- If you paste a long doc and ask questions, that doc occupies context. Long answers also occupy context. More context = more memory used.
- Attention = everyone-at-the-party checks everyone else.
- Each new word the model writes asks, “Which previous words matter?” That cross-checking scales badly as things get longer.
- KV-cache = sticky notes the model keeps so it doesn’t re-read everything from scratch.
- It stores “keys” and “values” (summaries of prior tokens) in GPU memory so future tokens can reference them quickly.
Here’s the kicker:
The Quadratic Problem (The Part That Eats Compute)
If you double the total length (prompt + the model’s long chain of thought), the memory needed to hold those sticky notes doesn’t just double—it quadruples. That’s the dreaded quadratic growth.
- Long reasoning = long chains of thought = huge KV-caches parked in precious GPU memory.
- Huge caches mean your server can handle fewer people at once (smaller batch size).
- Fewer people per GPU = sky-high cost per user.
Analogy: Imagine a pizza oven (the GPU). Short orders (simple chats) let you bake many pies at once. An order for a 2-meter wedding pizza (reasoning) hogs the oven so others wait—and your price per slice jumps.
How Smart Models Cheat the Bill (In a Good Way)
Two big efficiency tricks you’ll hear about:
- Mixture of Experts (MoE):
- Instead of sending every sentence to a 600-billion-parameter brain, you route it to a few relevant “experts” (say, ~37B active). It’s like seeing a specialist instead of the entire hospital staff. Result: Big-brain performance without paying for every neuron every time.
- Multi-head Latent Attention (MLA):
- A newer attention approach that cuts memory usage dramatically versus vanilla transformers. Less KV-cache bloat = more room in the oven.
DeepSeek’s magic: They leaned on MoE + MLA, and—when hardware interconnect was limited—they literally wrote custom low-level code (below typical libraries like NCCL) to schedule communication across GPUs. Translation: They squeezed every last drop from the chips they had.
Check out this video to learn more about MOE.
Back to the Geopolitics (aka The “Ship War”)
Why does Washington care so much?
- Military & strategic edge: If “whoever builds the smartest AI first” gets a compounding advantage, that’s national security 101.
- Two goals of export controls:
- Slow down training of giant models.
- Cap the total compute available for inference (day-to-day running), which limits how much AI can be deployed at scale.
Why does Beijing persevere?
- Industrial capacity: China can build big—data centers, power plants—fast. Lift restrictions and they could spin up massive compute farms.
- Shift to trailing-edge chips: While the bleeding edge slowed, production of “good enough” chips for cars/appliances boomed.
Why does Taiwan matter so much?
- TSMC’s foundry dominance: It aggregates global demand to fund mind-bendingly expensive fabs. Elite R&D clusters live in Hsinchu (Taiwan), Hillsboro (Oregon), Pyeongtaek (South Korea). That concentration is a strength—and a risk.
What about those loopholes?
- Cloud rental: Historically, some Chinese firms rented large GPU clusters from Western clouds. New “AI diffusion” rules aim to curb that by limiting cluster sizes that allies can sell/rent onward.
- Smuggling: High value per kilogram means… creative logistics—sometimes via friendly hubs.
How This Touches Your Everyday AI :)
- “Fast” vs. “Thinks for a while”: If a product gives you a “deep reasoning” toggle—or shows “thinking…” for longer—you’re paying for test-time compute. Nice answers cost more.
- Context matters: Long prompts + long answers balloon memory. Tools that summarize inputs or hide their chain-of-thought are controlling your cost.
- Availability & price swings: If chips are scarce or restricted, cloud prices jump. You’ll see it as usage caps, slower free tiers, or premium pricing for “reasoning mode.”
Key Takeaways (Put This in Your Notes App)
- Compute is the oil of AI. Not just for training (like in a couple of years). Running smart (reasoning) models at scale is the real budget killer.
- Memory is king for reasoning. KV-cache grows quadratically with context. That’s where money goes (and why most labs are not making money).
- Smarter architectures win. MoE + memory-savvy attention (like MLA) can slash costs without dumbing things down (this is where the competitive advantage lies—new math to reduce the bills).
- Geopolitics sets the speed limit. Export controls try to cap total deployable AI, not just stop headline-grabbing training runs (but the consequences of this seem to produce contrary effects, cf. DeepSeek).
- TSMC is the keystone. Taiwan’s fabs are the bottleneck everyone depends on—hence the global stakes.
Practical Playbooks (Whether You’re a User, Builder, or Exec)
If you’re a casual user
- If you’re paying per token, use “fast” mode for simple tasks; save “reasoning” mode for the gnarly stuff.
- Trim your prompts. Shorter context = less memory = cheaper, faster answers.
- Save and reuse good prompts (or templates). Repetition is efficient.
- If you're only paying the subscription fee, investors (or Google) are covering the real costs for now. Be prepared for a future where AI services may become more expensive.
If you build products
- Architect for memory: Prefer MoE-style models or ones with lighter attention variants.
- Constrain context: Summarize prompts, chunk docs, stream results. Add guardrails to stop run-away chains of thought.
- Batch smartly: Design UX that tolerates small delays to co-batch requests (dramatically lowers cost).
- Cache aggressively: Reuse embeddings, partial results, and KV where safe.
- Pick hardware for the job: For heavy reasoning, more HBM and solid interconnect can beat sheer FLOPS.
If you run a team or budget
- Separate SKUs: “Chat” (cheap) vs. “Reason” (premium). Price accordingly.
- Track tokens × latency × batch size. Those three explain your bill.
- Diversify vendors and regions to avoid single-point supply shocks.
- Educate stakeholders: long answers aren’t just slower; they’re exponentially pricier.
Frequently Asked (in Plain English)
Q: Why do some answers cost $10?
Because the model wrote a lot to itself before talking to you (reasoning). Those internal “drafts” live in memory that scales quadratically with length.
Q: Are cheaper chips useless?
No. For many tasks, memory-rich “mid” chips with good interconnect (even with lower FLOPS) can be fantastic.
Q: Will this all just get cheap soon?
It’ll get cheaper per unit, but demand explodes faster (Jevons paradox). Net: we’ll do way more with AI, and total spend still rises.
Q: Why does everyone worship TSMC?
Because they can actually make the cutting-edge stuff at scale. Talent density + process discipline = magic.
A Quick, Friendly Glossary
- FLOPS: How fast a chip does math.
- HBM (High-Bandwidth Memory): Super fast on-package memory—gold for big contexts.
- Interconnect: How quickly chips talk to each other (think data-center gossip speed).
- Inference: Running the model to get answers.
- MoE (Mixture of Experts): Only the relevant parts of a huge model wake up per request.
- KV-cache: Saved “notes” (keys/values) so the model doesn’t re-read the whole conversation each time.
- Quadratic: Double length → 4× memory. Ouch.
Where This Goes Next (And How to Prepare)
- Models: More MoE, smarter attention (reasearch), and on-the-fly compression of KV-cache.
- Hardware: Memory-heavier GPUs, faster interconnects, and specialized accelerators focused on serving (not just training).
- Policy: Tighter rules on cloud rentals and cluster size; more domestic fab building; more supply-chain redundancy.
- You: Treat “reasoning” as a premium resource. Spend it where it pays back—deep research, code generation, planning, high-stakes decisions.
Wrap Up
The chip war isn’t abstract. It shows up every time your AI takes a breath to “think.” Memory isn’t boring plumbing—it’s the price meter. And the global fight over who controls that meter will shape everything from your app’s UX to your quarterly budget.
You don’t need to fear the acronyms. You just need to know which ones move your bill. Now you do.
Until the next one,
— Charafeddine