
Hey friend,
Let me tell you a quick story you’ve probably lived yourself.
You open YouTube “for 5 minutes.”
Two scrolls later, there he is.
Soft voice. Serious face. Academic vibe.
Title underneath: “AI Will End Humanity (Sooner Than You Think)”

You click.
Within 20 minutes, you’ve learned:
- AI is a black box nobody understands.
- Superintelligence is inevitable and uncontrollable.
- 99% of jobs will disappear.
- There’s a 99.9% chance humans go extinct.
- Timeline: basically… 2027–2030.
You close the app and just sit there.
“Why am I even trying to learn anything?”
“Why build a career if AI takes every job?”
“Why save for my kids’ college if we might not be here?”
Welcome to the age of the AI end-times prophet.
And right now, the most visible one is Dr. Roman V. Yampolskiy.
I'm writing this because in "The Diary of a CEO" podcast, Roman Yampolskiy was asked: "What are the arguments of people who don't agree with you?" His answer (something like): "It's usually people who haven't read the literature—some engineer working on an ML model maximizing clicks, saying that AI is not good enough." I was surprised by how shallow this answer is, and therefore I decided to share a complete breakdown of why this "toxic ideology" is just wrong—using the "literature."
1. The "Prophet" of Doom
Roman Yampolskiy is not a random Twitter doomsayer.
He’s:
- A computer science professor at the University of Louisville
- Director of their Cybersecurity Lab
- A long-time AI safety researcher
- Author of AI: Unexplainable, Unpredictable, Uncontrollable and Considerations on the AI Endgame
Over the last ~18 months, his core message has been blasted everywhere:
- Lex Fridman Podcast — where he talks about a 99.9% chance that advanced AI wipes out humanity within the next 100 years.
- Diary of a CEO — where he’s introduced with lines like “AI could end humanity,” “99% of jobs gone,” and “superintelligence could trigger collapse by 2027.”
- Joe Rogan Experience — the biggest podcast on the planet, revisiting the themes of uncontrollable superintelligence, job loss, collapse as the “default.”
Tech media amplifies it further: headlines about “99.9% chance AI destroys humankind” do serious numbers.
If you’re a normal person, stressed and busy, the story that hits your brain is simple:
AGI might arrive around 2027. By 2030, 99% of jobs could be gone. Long term, there’s a 99.9%+ chance AI wipes us out.
This isn’t marketed as a spooky sci-fi thought experiment. It’s presented as math, science, and “I hate to say this but…” expertise.
And he’s not alone. Elon Musk has spent years calling AI “the biggest existential risk” to humanity, sometimes tossing out his own extinction odds (10–20%) and painting a picture of a future superintelligence treating us like ants.
Stack it all together and you get a high-impact, emotionally loaded narrative:
“A godlike AI is coming soon.
It will take almost all jobs.
We probably can’t control it.
The default outcome is collapse or extinction.”
That story hits hard. Not because it’s carefully reasoned, but because of what it does to you:
- It collapses all possible futures into one: doom.
- It frames participating in AI (learning, building, experimenting) as morally suspicious.
- It encourages you to stop — stop learning, stop building, stop planning.
This newsletter — this special edition of AI OS — is going to do the opposite.
I’m going to:
- Explain the AI doom arguments in simple language you can repeat to anyone.
- Show you where the logic quietly jumps off a cliff.
- Give you a more realistic way to think about AI risk so you can actually act — not freeze.
No hand-wavy optimism. No “trust the vibe.”
We’ll grant the math where it’s real… and then show you why the “99.9% doom by 2027” stuff does not follow.
I've written about this before, but today we're going deeper, this is a Special Edition.
I need you focused. Grab a coffee, sit down, and fire up your neurons. Let's go.
2. The Doom Story in Plain English
Let’s be fair and steelman the doomer argument first — especially Roman’s.
The core thesis (in normal language)
Roman’s core message in AI: Unexplainable, Unpredictable, Uncontrollable goes like this:
1. We can’t fully understand advanced AI
As models get bigger and smarter, their internal workings become “black boxes.”
Translation: we don’t really know why they do what they do…and that’s true.
2. We can’t reliably predict what a superintelligent AI will do
Using ideas from chaos theory and computer science, he argues that a system smarter than us is, by definition, hard or impossible to predict.
Translation: if it’s smarter than you, you can’t predict all its moves.
3. We can’t truly control it
If you can’t fully understand or predict a system, you probably can’t control it — at least not in the strong, guaranteed sense.
Translation: we’re building a mind we can’t restrain.
4. Mathematics says “control is impossible” in general
He uses computer science results like the halting problem and Rice’s theorem to argue that there is no general algorithm that can look at any AI and say “this one is safe” in all situations.
Translation: there is no perfect “safety checker” that works on all future AIs.
Therefore:
- We can’t prove that superintelligent AI will be safe.
- We can’t guarantee we’ll keep it under control.
- If we create something vastly smarter and faster than us, we’re almost certainly toast.
He then jumps to:
- 99.9%+ chance AI destroys humanity
- 99% of jobs gone by 2030
- AGI around 2027
That’s the doom pipeline.
Let’s put it in one sentence:
“Because math says we can’t perfectly prove or predict AI safety in all cases, any path to advanced AI almost certainly ends in extinction — very soon — after it takes almost all jobs.”
Heavy.
Before we tear into that, let’s make this concrete.
3. Why This Narrative Feels So Convincing
You’re not dumb for finding this scary. The narrative is designed (intentionally or not) to stick.
Here’s why it lands so hard:
1. It uses real math words.
“Undecidability”, “computational irreducibility”, “impossibility theorem” — these aren’t fake. They’re actual computer science concepts. The trick is how they are applied.
2. It’s simple and cinematic.
“Unexplainable, unpredictable, uncontrollable” — that’s a movie tagline. It feels satisfying: three words, one villain.
3. It gives you a clean identity:
“You’re wise and responsible if you’re scared. You’re naive or reckless if you’re not.”
4. It relieves responsibility.
If doom is 99.9% inevitable, you don’t have to build anything, learn anything, or make hard decisions. You can just… spectate the apocalypse.
And this is the real danger:
It doesn’t just warn you.
It paralyzes you.
We’re not going to respond with “don’t worry, bro, everything’s fine.” That’s just the mirror image of the same laziness.
Instead, we’re going to:
- Take his strongest arguments
- Translate them into plain language
- Show you exactly where they overstep
Think of this as a mental vaccine.
4. The Three Pillars of AI Doom (Explained Simply)
Roman’s book title is a neat summary:
Unexplainable. Unpredictable. Uncontrollable.
Let’s unpack each one in human language.
4.1 “Unexplainable”: The Black Box Problem
The argument:
“Modern AI systems, especially deep learning models, are so complex that we can’t fully explain why they make specific decisions. If we can’t explain them, we can’t be sure they’re safe.”
This is partially true.
- Large neural networks have millions or billions of parameters.
- Their “reasoning” is distributed across many neurons and layers.
- Explaining exactly why a specific output happened can be hard or impossible.
Example:
Ask a big language model why it wrote a particular paragraph.
You can get a story after the fact, but that story isn’t the low-level, neuron-by-neuron truth. It’s like a human explaining why they fell in love — a narrative, not a circuit diagram.
So yes: complete micro-level explainability is unrealistic.
Doom jump:
Therefore, we can’t know if it’s safe.
Therefore, we can’t use it safely.
Therefore, doom.
Hold that — we’ll come back to it.
4.2 “Unpredictable”: Smarter Than the Predictor
The argument:
“You can’t predict what an agent smarter than you will do. If we make something vastly smarter, its behavior is inherently unpredictable. Unpredictable = unsafe.”
He leans on:
- Chaos theory (tiny changes → big effects)
- Computational irreducibility (some systems can’t be shortcut; you have to simulate them)
- “Smarter-than-human” systems being fundamentally outside our forecasting ability
On some level, again, this makes sense.
- You can’t predict every move of a better chess player.
- You can’t foresee every path a complex system could take.
- You definitely can’t enumerate all ways a superintelligent agent could hack, manipulate, or escape.
So yes: perfect prediction of all future behavior isn’t on the menu.
Doom jump:
If we can’t predict everything, then we can’t control anything.
If we can’t control anything, the default is extinction.
Again: hold that.
4.3 “Uncontrollable”: The Halting Problem Meets Skynet
This is where the math comes in.
Roman pulls from fundamental computer science results like:
- Halting Problem – There is no general algorithm that can look at any program and prove whether it will eventually halt or run forever.
- Rice’s Theorem – There is no general algorithm that can look at any program and decide any non-trivial semantic property of that program (like “is this safe?”).
He then argues:
- A superintelligent AI is just a very advanced program.
- “Containment” means: having a general procedure that can decide if any such AI will stay within safe bounds forever.
- Halting + Rice say such a universal procedure can’t exist.
- Therefore, AI control is “mathematically” impossible.
Doom jump:
If we can’t mathematically prove safety for all possible AIs in all possible scenarios, then any attempt to build advanced AI is basically suicide.
You can see how that lands with authority:
“This isn’t my opinion.
This is math.”
Except… that’s not what the math says for the real world.
Time to flip the board.
5. Where the Logic Actually Breaks
We’re going to keep this grounded and visual.
5.1 You Don’t Need Perfect Control to Be Safe
Roman treats “control” like this:
Either we have a perfect, deterministic guarantee that an AI will never ever misbehave in any possible situation…
or it’s “uncontrollable.”
That’s not how literally any engineered system works.
We use a different definition in practice:
Control (engineering style):
Design the system + environment so that the probability of bad behavior stays below some acceptable threshold, under a well-defined set of conditions.
We do this everywhere:
1. Aviation:
We can’t predict every turbulence pattern, but we design planes, procedures, and training so that flying is extremely safe per mile.
2. Computer networks:
We don’t have a proof that “no weird sequence of packets will ever crash anything,” but we design protocols, test them, and add fallback mechanisms.
3. Cryptography & OS security:We don’t have a magic oracle that checks any arbitrary program for vulnerabilities.Instead, we:
- Use restricted languages & frameworks
- Verify critical components formally
- Add sandboxes, permissions, monitoring, and patches
In other words:
Safety is almost never “perfect or nothing.”
It’s layers of defense + bounded risk.
The halting problem and Rice’s theorem are about universal, once-and-for-all guarantees for all possible programs.
That’s like saying:
“We can’t build a machine that detects every bug in any possible software, so… no software can ever be safe to use.”
You obviously don’t live your life like that. If you did, you’d throw out your phone, bank, and plane tickets.
Key takeaway:
The math kills the dream of a perfect safety oracle for all hypothetical superintelligences.
It does not say we can’t build any AI system that’s safe enough in the real world.
5.2 Real AI Systems Are Constrained, Not Magical
When doomers talk, they often describe AI as this godlike fog:
“It will escape. It will hack everything. It will take over the world.”
In reality, today’s advanced AI looks more like:
- A big probability machine that predicts text (or images, or actions)
- Wrapped in normal software
- Running on someone’s servers
- Inside an operating system
- Inside a network with permissions, firewalls, logging, etc.
It doesn’t:
- Spontaneously wire itself into nuclear silos.
- Summon robot armies from the void.
- Rewrite its own physical substrate.
All of that requires code written by humans + infrastructure built by humans.
We can:
- Restrict what actions an AI can take (which APIs, which tools).
- Sandbox what it can touch (no internet, no filesystem, limited system calls).
- Monitor its behavior (logging, anomaly detection, guardrails).
- Force critical operations through human approval.
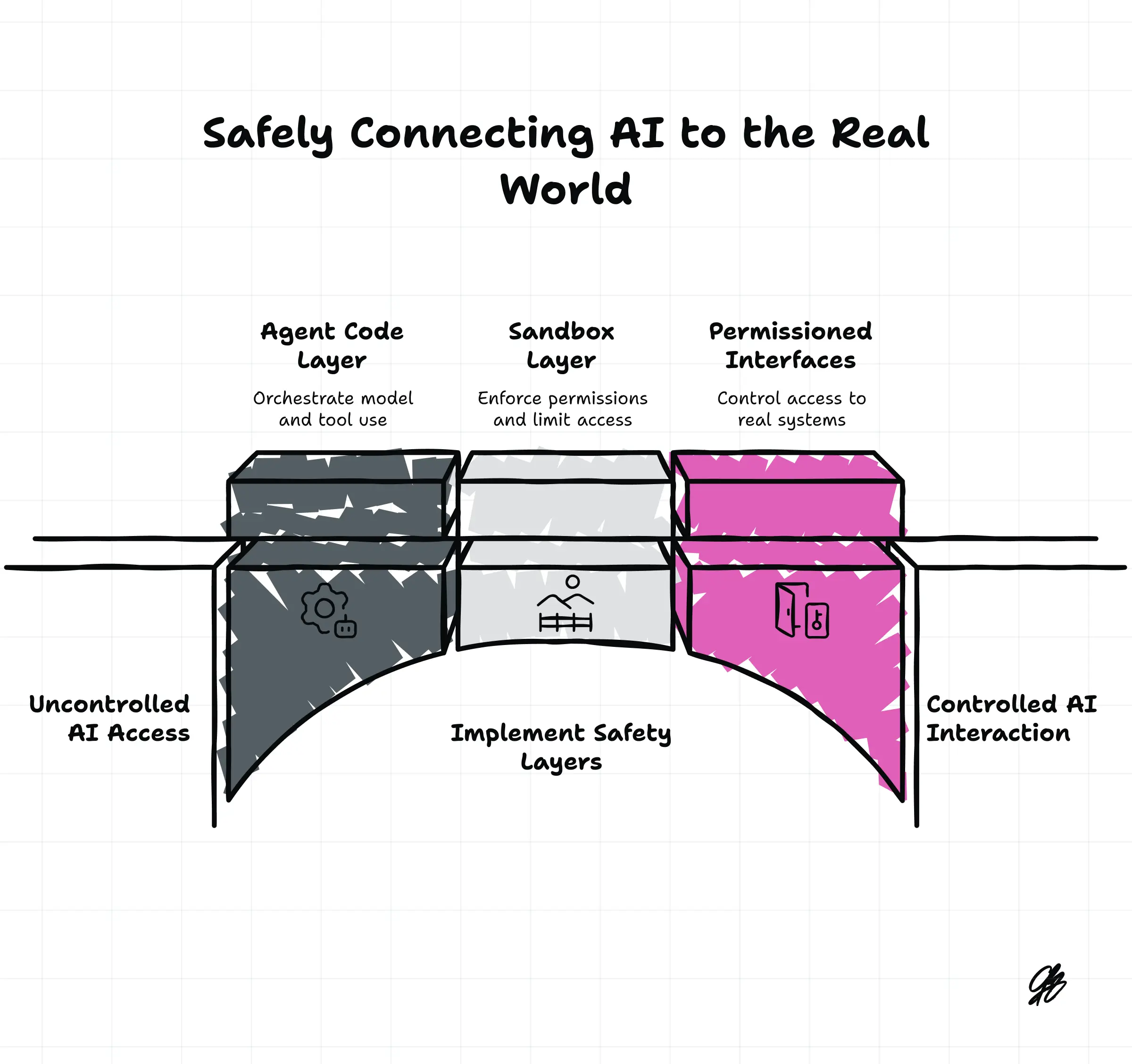
Is this perfect? No.
Is it “mathematically impossible”? Also no.
Roman’s math theorems assume:
“an arbitrary, unconstrained program in a fully general environment.”
Our actual systems are:
“concrete programs in heavily constrained environments with human checks.”
Very different beasts.
5.3 Unpredictable ≠ Unusable
Another hidden assumption:
“If we can’t predict exactly what a system will do in all situations, it’s uncontrollable.”
If that were true, humans would be illegal.
We already rely on systems that are:
- Messy
- Stochastic
- Not fully explainable
Examples:
- You can’t predict exactly how the stock market will behave. You still invest.
- You can’t predict every move your coworkers will make. You still work with them.
- You can’t predict every outcome in a hospital, but you still go when you’re sick.
We manage risk with:
- Rules, incentives, and laws
- Redundancy and oversight
- Firebreaks: ways to stop cascading failures
With AI, it’s similar:
We can’t say “this LLM will never say anything harmful in any possible future.” But we can:
- Filter outputs and prompts
- Limit domains (e.g., medical support tools that never act directly, only suggest to doctors)
- Add human-in-the-loop checkpoints
- Use multiple models to cross-check each other
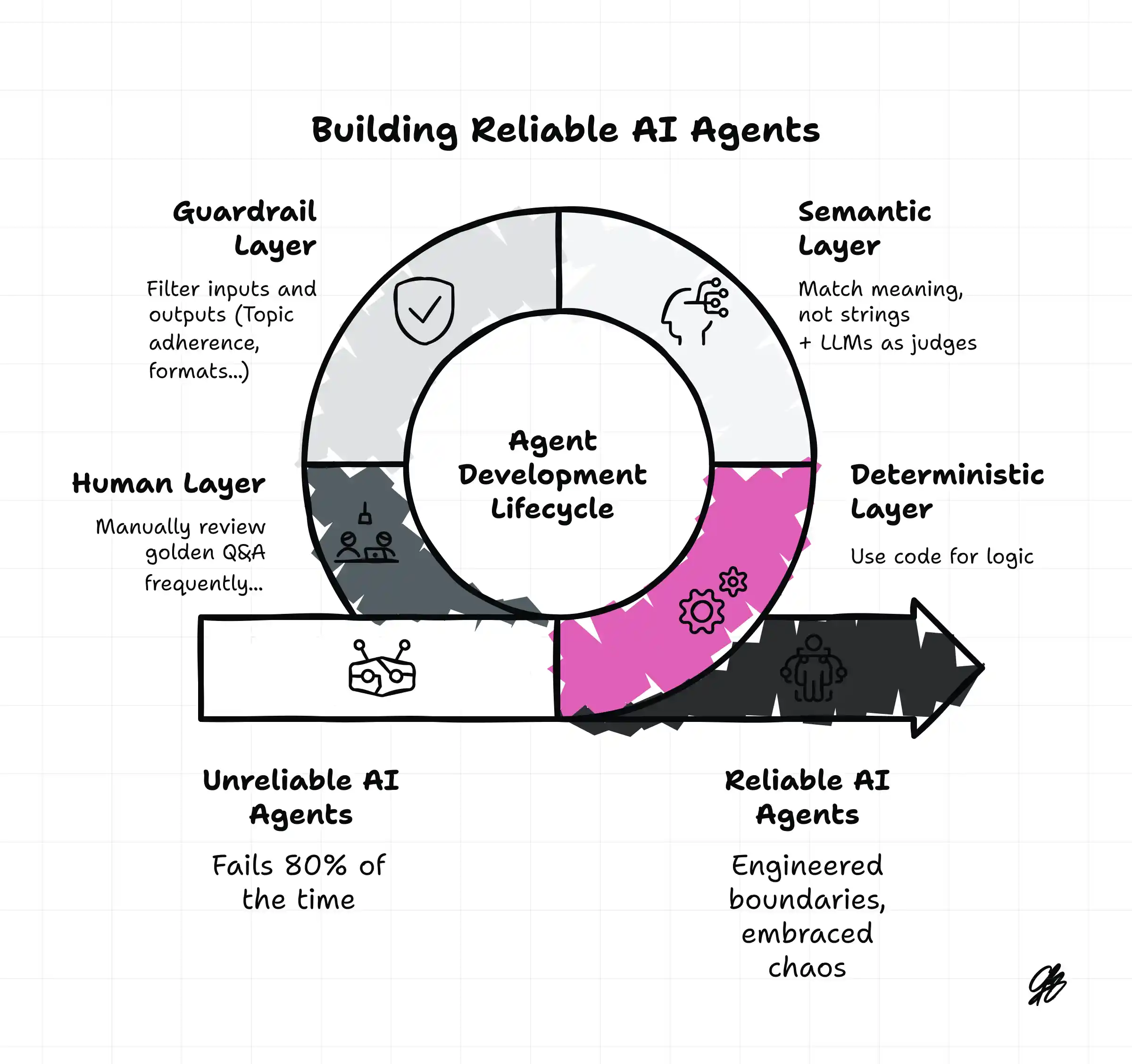
Again: not perfect. But calling that “uncontrollable” is like calling cars uncontrollable because we can’t mathematically prove no one will ever crash.
5.4 “Black Box” Doesn’t Mean “No Safety”
Roman’s unexplainability point is real: we won’t understand every neuron of advanced systems.
But here’s the key distinction:
We don’t need full internal understanding to have external safety.
We do this already:
- You don’t know every transistor in your CPU, but you trust your laptop because of testing, standards, and layers of abstraction.
- You don’t understand every molecule of a drug, but we still use it with clinical trials, dosage, and monitoring.
With AI, we can focus on:
- What it’s allowed to do (capabilities, permissions)
- How its outputs are used (never directly wiring it into critical systems without checks)
- What invariants we enforce (e.g., “this process cannot send network requests directly”)
You can think of it like raising a teenager with superpowers:
- You might not know every thought in their head.
- But you can:
- Decide what keys they have access to
- Set rules
- Install cameras in the lab
- Limit what chemicals they’re allowed to touch
Is that enough to make risk zero? No.
Is it automatically “99.9% chance of extinction”? Also no.
Key takeaway:
Unexplainable inside ≠ unmanageable outside.
5.5 The 99.9% Doom Number is Not Science
This part is important:
There is no serious mathematical model that outputs
“99.9% chance of extinction from AI.”
To get numbers like that, you’d need:
- A defined space of possible AI trajectories
- A prior over that space
- A model of how different designs map to outcomes
- Evidence that dramatically collapses your uncertainty
We don’t have that.
Not even close.
So when someone says “99.9% chance of doom,” what they’re really saying is:
“Emotionally, I feel this is almost certainly going to kill us.”
You’re allowed to feel that.
You’re not allowed to pretend the feeling is a theorem.
Same with:
- “99% of jobs gone by 2030”
- “AGI by 2027”
Those are guesses, not outputs of computer science.
6. About That “99% of Jobs Will Vanish by 2030” Thing
Let’s isolate the job claim, because this one hits people right in the gut.
The doomer version:
“By 2030, AI will take 99% of jobs. Only a tiny handful of roles will remain.”
What this implies:
- Most of the economy is fully automated in ~5–7 years.
- Robotics, logistics, manufacturing, healthcare, education, services — everything.
- Society just… smoothly accepts this and reconfigures in record time.
Now, let’s be adults:
6.1 Yes, AI is going to disrupt a lot of jobs
- A ton of knowledge work is becoming augmented or partially automated.
- Repetitive digital tasks are on the chopping block.
- Some roles will shrink or disappear; others will explode in demand.
You should absolutely take this seriously for your own career.
Ignoring AI in 2025+ is like ignoring the internet in 2000.
But…
6.2 99% by 2030 is not a math result
It ignores:
- Robotics & physical reality
- Replacing a cashier interface is easy. Replacing every plumber, nurse, construction worker, and chef with robots in 5–7 years? That’s an entire world of hardware, regulation, and adoption.
- Regulation & politicsIf AI wiped out huge job sectors overnight, you’d see:
- Laws
- Unions
- Court cases
- Political upheaval
- None of that appears in a neat, smooth, 5-year graph.
- New job creationEvery big wave of automation has created new categories:
- Industrialization → factory jobs, managerial roles
- Computers → software, IT, design, digital marketing
- Internet → creators, platform businesses, remote work ecosystems
AI is no different. It will kill some jobs, morph others, and create new ones.
No theorem can tell you “exactly 99% of jobs vanish by precisely 2030.” That’s not computer science. That’s speculative futurism dressed up as inevitability.
Key takeaway:
“AI will change the job market a lot” = true.
“99% gone by 2030” = marketing, not math.
7. A More Honest, Useful Way to Think About AI Risk
Let’s throw out both extremes:
- “We’re all dead, don’t bother”
- “Nothing bad can happen, just ship”
Here’s a more grounded frame.
7.1 What the math actually tells us
Computer science results (halting problem, Rice’s theorem, etc.) tell us:
- There is no universal, perfect algorithm that can look at any possible advanced AI and say “safe” or “unsafe” for all environments.
- We can’t rely on absolute formal guarantees for every future agent.
That means:
- No single magic safety switch.
- No “one proof to rule them all.”
It does not mean:
- “We cannot build any safe systems.”
- “All advanced AI leads to extinction.”
7.2 What engineering practice tells us
Decades of building complex, critical systems tell us:
We can:
- Restrict what systems can do
- Verify important components
- Sandbox them
- Add monitoring, failsafes, and human oversight
- Iterate when things break
Risk is reduced through:
- Architecture
- Process
- Governance
- Culture
Not one magical theorem.
7.3 Where the real work is
The real AI safety work looks like:
- Designing bounded agents with limited actions
- Separating reasoning systems from actuators (the things that touch the real world)
- Building monitoring tools that catch anomalies and escalate to humans
- Creating regulations and standards for high-risk domains
- Running red teams and stress tests on powerful models
- Having serious conversations about what not to build
Is there a non-zero risk of something going horribly wrong?
Yes.
Do we know the exact probability?
No.
Is “99.9% doom by 2030” a serious, evidence-based number?
Also no.
8. What This Means For You (The Practical Part)
Let’s bring this back to your actual life.
The doomer narrative quietly encourages you to:
- Pause your learning (“what’s the point?”)
- Delay projects (“we’re dead by 2030 anyway”)
- Avoid AI entirely (“using it is complicit in doom”)
That’s a fantastic way to lose.
Instead, here’s a more useful stance:
Assume AI will be a big deal, assume non-zero risk, and act like a builder — not a spectator.
Some concrete shifts:
8.1 Stop doom-scrolling, start model-building
Next time you hear:
“We almost certainly lose.”
“99% of jobs gone.”
“Control is mathematically impossible.”
Run it through this filter:
- Is this a theorem about all hypothetical superintelligences… or about the actual systems we have?
- Is this person distinguishing between “no perfect guarantee” and “no practical control”?
- Are they giving you actionable paths forward, or just vibes?
If it’s all certainty + no nuance + no action steps, treat it as emotional content, not scientific guidance.
8.2 Use AI, don’t worship or fear it
Think of AI as:
A super-charged tool that can:
- compress knowledge,
- accelerate your work,
- and require new safety layers.
The best position to be in over the next decade is:
- Someone who understands how these systems work at a high level
- Someone who knows where they break
- Someone who can use them to create value safely
That might be as:
- A founder building AI-augmented products
- A professional using AI to 2–5x your output
- A policymaker who understands the tech enough not to be hypnotized by doomer marketing
8.3 Talk about AI like an adult, not a cult member
By the end of this letter, you should be able to explain to a friend:
- What Yampolskiy’s main arguments are (black box, unpredictability, undecidability)
- What those math results actually say (no perfect safety oracle)
- Why that doesn’t logically equal “99.9% chance we all die soon”
- Why we can both:
- take AI risk seriously
- and still build, learn, and plan
That’s the real goal:
Not blind faith. Not blind fear.
Just clear thinking.
9. Simple Recap (Your “Explain-It-To-Anyone” Cheat Sheet)
Use this as your mental flashcard.
Q: Why are some people saying AI will almost certainly kill us?
A: They argue AI will be unexplainable, unpredictable, and uncontrollable. They lean on computer science theorems saying we can’t have a perfect, universal safety-checking algorithm.
Q: Is it true that we can’t fully prove advanced AI is safe in all cases?
A: Yes. Math shows no general algorithm can certify every hypothetical AI in every environment.
Q: Does that mean any advanced AI will almost certainly cause human extinction?
A: No. That jump is emotional, not mathematical. We rarely have perfect guarantees in engineering, but we still build systems that are safe enough through constraints, oversight, and design.
Q: What about 99% of jobs being gone by 2030?
A: There’s no serious math behind that number. AI will definitely reshape the job market, but “99% gone by 2030” is speculation, not a theorem.
Q: So how should I think about AI?
A: As a powerful tool with real risks and real upside. Not a magic god, not a guaranteed apocalypse. Learn how it works, use it to build, and support sensible guardrails.
10. Closing Thoughts: Refusing the Bedtime Story
The “AI will end humanity” narrative feels like a bedtime story for adults:
- Clear villain
- Clean plot
- Tragic ending
- Your role: helpless witness
It’s seductive because it simplifies a messy, uncertain future into one path.
Real life is messier:
- The math has hard limits, but not definitive outcomes.
- The tech is powerful, but not omnipotent.
- The risks are non-zero, but not pre-written.
You don’t need to pick a side between “cheerleader” and “doomer.”
You can pick the third option:
Builder with eyes open.
Use AI. Study its limits. Push for sane safety work.
But don’t hand over your agency to someone on a podcast who tells you the game is already over.
It isn’t.
You’re in it.
Talk soon,
— Charafeddine (CM)
P.S. If this helped you shift how you think about AI doom, forward it to someone who’s been low-key paralyzed by the apocalypse headlines. The more adults we have in the room, the better this decade gets.