
Imagine if your calculator could show its work like a math student, or if your chatbot paused to reason through a tricky question instead of blurting out an answer. Welcome to the world of reasoning models – AI systems designed to break down problems and solve them with step-by-step logic, much like we do. In this deep dive, we’ll explore how these models work, how they’re trained, and how different approaches (from DeepSeek R1 to OpenAI’s models and Llama variants) compare. We’ll keep things friendly and accessible – even sprinkling in an explanation fit for a 12-year-old – so regular folks and curious developers alike can grasp how AI learns to think.
What Are “Reasoning Models” in AI?
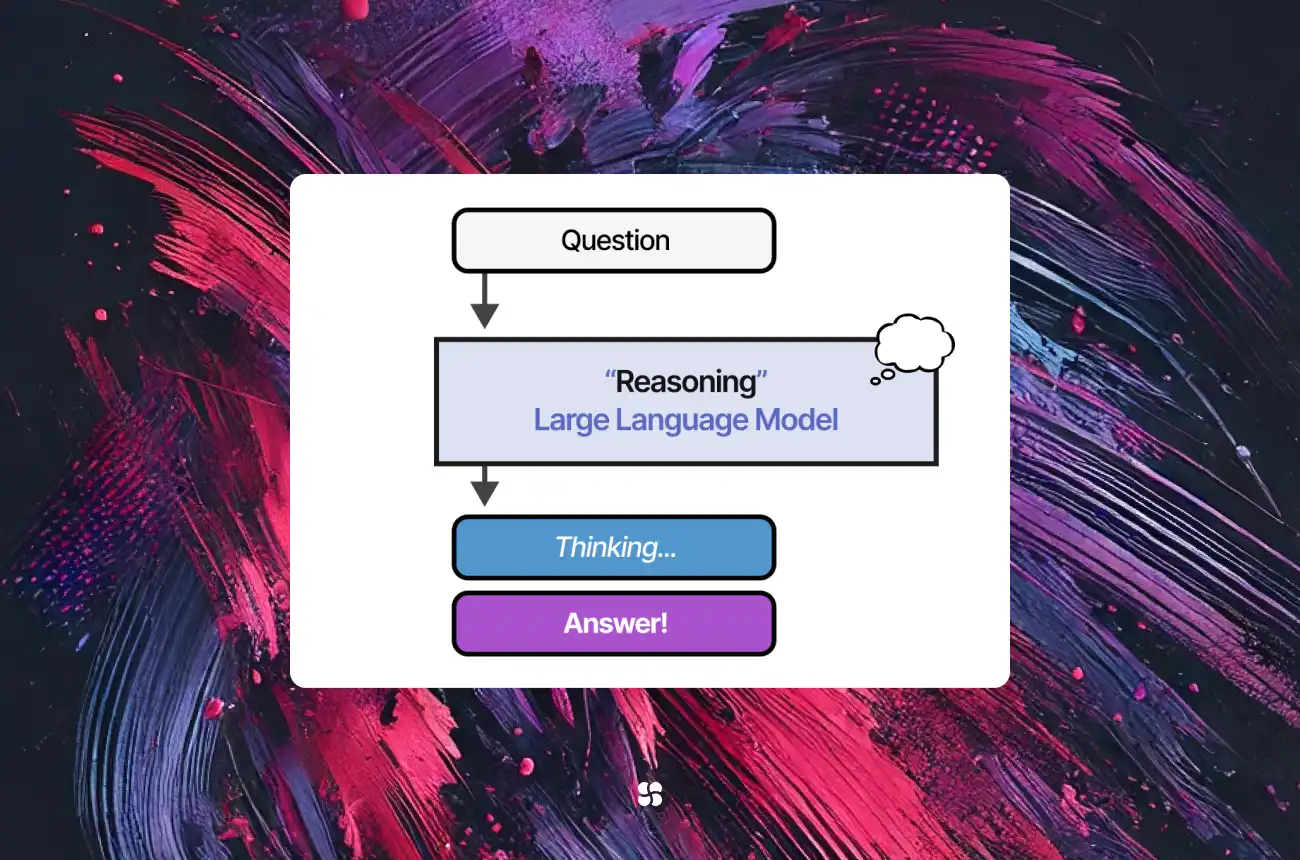
Reasoning models are advanced AI language models that don’t just spit out answers – they show their thought process. Unlike earlier AI that might give an answer with no explanation, a reasoning model solves complex problems by breaking them into smaller steps and reasoning out loud (internally or visibly). This step-by-step approach is often called “chain-of-thought” (CoT) reasoning, referring to the chain of intermediate steps the model goes through.
Why is this a big deal? Because it lets the AI verify or check itself as it goes, a bit like “thinking about thinking.” In fact, researchers describe this as a form of metacognition – the model reflecting on its own reasoning. By working through problems methodically, the AI can catch mistakes, correct its course, and reach more reliable answers. We’re essentially putting some wisdom into these models so they don’t just regurgitate info, but actually reason with it.
For example: A regular language model might be asked, “How many Rs are in the word ‘strawberry’?” and quickly (and carelessly) answer “2”. A reasoning model, on the other hand, would internally go through each letter: “strawberry – let’s list the letters: s, t, r, a, w, b, e, r, r, y. Now count the R’s… there are 3!” Then it would answer “3”. By breaking the task into steps (spell -> count), the reasoning model avoids the mistake and answers correctly.
This idea might sound straightforward, but it represents a paradigm shift in AI. It’s the difference between an AI that guesses versus one that thinks things through. And interestingly, researchers discovered that large language models already had a knack for this kind of reasoning – if you just asked them the right way. In a 2022 study, simply prompting a big model to “think step by step” led to significantly better performance on math, logic, and commonsense questions.
In fact, with a few examples of reasoning given in the prompt, a 540-billion-parameter model hit state-of-the-art on a math word problem benchmark – even beating a fine-tuned GPT-3 model! This showed that LLMs could reason, but they often needed a nudge (in the form of a prompt) to do it.
Reasoning models take this a leap further: they don’t need to be asked to show their work – they’re trained to do it by default. They have internalized the “think step-by-step” habit as part of their model behavior. When faced with a hard question, a reasoning AI will automatically engage its chain-of-thought, almost like how you or I might scribble notes on scratch paper when solving a puzzle. This usually means it may take a bit longer to answer (it’s essentially doing more computation by reasoning through the steps), but the answers will generally be more accurate for complex problems.
As one AI researcher quipped about OpenAI’s new reasoning model (code-named “o1”), “Many tasks don’t need reasoning, and sometimes it’s not worth it to wait for an o1 response vs a quick GPT-4 response.”. In other words, if you ask a simple question like “What’s 2+2?”, a regular model and a reasoning model will both get it right – but the reasoning model might take a few extra seconds explaining “First I take 2 and add another 2 to get 4”. For trivial queries, that is overkill. But for hard problems, this extra thinking time is exactly what makes the difference between a sloppy guess and a correct solution.
How Do Reasoning Models “Think” Differently?
Let’s break down what’s happening inside a reasoning AI’s mind (figuratively speaking):
- Chain-of-Thought (CoT): This is the internal dialogue or scratchpad the model uses. Think of it as the model’s thought bubble. Instead of jumping straight to an answer, the model generates a sequence of intermediate thoughts: mini-conclusions, calculations, or logical steps. For example, if asked, “Is 9.11 greater than 9.8?”, a reasoning model’s chain-of-thought might be: “Compare 9.11 and 9.8 as decimals. 9.11 is 9 + 0.11, and 9.8 is 9 + 0.8. Since 0.8 is greater than 0.11, 9.8 is larger.” Finally it outputs the answer: “9.8 is greater.” The chain-of-thought is like the model’s working notes – it dramatically improves the model’s ability to handle tricky questions. In fact, OpenAI observed that by training their model to use such a chain-of-thought and refine it, the model “learns to recognize and correct its mistakes… break down tricky steps… try a different approach when one isn’t working”, all of which “dramatically improves the model’s ability to reason.”.
- Self-Checking and Reflection: A reasoning model often will double-check intermediate results. It might re-evaluate a step and say “hmm, does that look right?” internally. This is similar to how you might pause and verify a calculation in the middle of solving a problem. Researchers have noted that advanced models sometimes show an “aha moment”, where the model “steps back, spots mistakes and corrects itself.” For instance, if a model working through a math proof realizes a prior step was wrong, it can revise that step and continue – rather than confidently carrying a mistake to the final answer (which standard LLMs often do). This ability to reflect and fix errors is a hallmark of reasoning models.
- Explainability: Because these models produce a reasoning trace, we get insight into why they gave an answer. This is huge from a user trust perspective. Instead of a black-box answer “because the model said so,” we can see the logical path taken. Some reasoning AIs will even expose this chain-of-thought to the end user. For example, the open-source DeepSeek-R1 model provides an API where along with the final answer, you can retrieve the model’s reasoning content (a full step-by-step explanation). Developers can use this to debug the AI’s thinking or even show the reasoning to users for transparency. (Of course, these reasoning traces are generated by the model and not guaranteed to be 100% foolproof logic – but they greatly help in understanding the model’s thinking.)
To illustrate, let’s actually see how one could query a reasoning model via code and get its chain-of-thought. We’ll use DeepSeek-R1’s API in this example:
from openai import OpenAI
# Initialize the DeepSeek client (DeepSeek uses an OpenAI-compatible API)
client = OpenAI(api_key="YOUR_DEEPSEEK_API_KEY", base_url="https://api.deepseek.com")
# Ask a question that needs reasoning
messages = [{"role": "user", "content": "9.11 and 9.8, which is greater?"}]
response = client.chat.completions.create(model="deepseek-reasoner", messages=messages)
# Extract the chain-of-thought reasoning and the final answer from the response
reasoning = response.choices[0].message.reasoning_content
answer = response.choices[0].message.content
print("Model's reasoning steps:", reasoning)
print("Model's final answer:", answer)Running this, the reasoning might contain something like: “I need to compare 9.11 and 9.8. Let’s convert to decimals with equal length: 9.11 vs 9.80. Clearly, 9.80 is larger than 9.11. Therefore, 9.8 is greater.” And answer would be “9.8 is greater.” This simple code snippet shows how a reasoning model not only gives an answer but also its thought process leading there.
Now that we know what reasoning models do, let’s talk about how on Earth we get an AI to behave like this. It turns out it’s not as simple as telling a model “please think more.” Researchers had to get creative with training techniques to cultivate these step-by-step reasoning skills in AI.
Training AI to Reason (Explained for a 12-Year-Old and Beyond)
Training a reasoning model is a bit like teaching a student good study habits. A student might know a lot of facts, but to solve a tough problem they need to learn to break it down, consider different approaches, and check their work. We want our AI models to develop those same habits. How do we achieve that? Let’s approach this in layers of complexity – first an analogy a 12-year-old could grasp, then the actual machine learning methods behind it.
Imagine you’re coaching two students to solve math problems:
- The first student, Alex, is given tons of practice problems with final answers only. Alex’s job is to memorize patterns and try to match the right answer. Sometimes Alex gets it right, but often if the problem is new or tricky, Alex might guess and make mistakes. Alex never learned how to solve, just what the end answers look like.
- The second student, Riley, is trained differently. When practicing, Riley is rewarded not just for the correct final answer, but for doing the right steps in between. You occasionally peek at Riley’s work and say “This step was correct (+1 point), that step was wrong (-1 point),” and so on. Over time, Riley learns how to think through the problems, not just what the answers are.
In AI terms, most traditional language models (like the original GPT-3) were trained more like Alex: they read millions of examples of questions and answers (and general text) and learned to predict answers. They weren’t explicitly shown the reasoning steps for complex problems – those had to be implicit in the data or figured out by the model on its own. Reasoning models are trained more like Riley: they get feedback on the process of solving problems, not just the final result, so they learn to develop a robust problem-solving approach.
Now, let’s map this to actual AI training techniques:
- Supervised Fine-Tuning (SFT) on Solutions: One way to teach reasoning is to directly show the model lots of examples of step-by-step solutions. For instance, you could take math problems or logic puzzles and provide annotated solutions with reasoning. The model is then trained to imitate those solutions. This is analogous to giving Riley a workbook of solved problems to study. OpenAI reportedly did something like this by hiring mathematicians and programmers to write out step-by-step approaches to problems, which were used to fine-tune their models. By seeing many examples of how to solve a task, the model starts learning the pattern of reasoning.
- Chain-of-Thought Prompting (at Inference): This isn’t exactly training, but it’s worth noting: before we had specialized reasoning models, a trick was to simply prompt the model with something like “Let’s think this through step by step” at query time. As mentioned, this prompting method revealed latent reasoning ability and boosted performance on complex tasks. Think of this as you, the user, encouraging Alex (from our analogy) to slow down and show work. It helps, but it’s not foolproof – you’re essentially hoping the model has learned a bit of reasoning during its general training and just needed a cue to use it.
- Reinforcement Learning (RL) for Reasoning: This has emerged as a powerful training approach for reasoning models. In reinforcement learning, we don’t directly tell the model the correct steps – instead, we define a reward (a score) to signal how well the model did, and let the model explore ways to maximize that reward. It’s trial-and-error learning, somewhat like training a dog with treats or playing the hot-and-cold game. For reasoning, the idea is: give a high reward when the model gets a problem correct (and perhaps when its reasoning steps are valid), and a low reward when it’s wrong. The model then adjusts its internal parameters to try to get more reward next time. Over many iterations, it figures out for itself that writing a chain-of-thought, checking its work, and so on leads to more correct answers – because those strategies yield higher rewards.
- This approach is exactly what the team behind DeepSeek-R1 did. They posed a bold question: “Can we just reward the model for correctness and let it discover the best way to think on its own?”. The result was stunning – through large-scale RL training, their model spontaneously developed sophisticated reasoning behaviors. Without anyone explicitly telling it how to reason, it learned to generate long logical chains, to reflect and double-check answers (self-verification), and to avoid obvious errors. In fact, DeepSeek-R1’s precursor model (R1-Zero) was trained via reinforcement learning without any supervised fine-tuning first, and it still managed to acquire impressive reasoning skills. This was a first proof that pure RL can induce reasoning in LLMs – essentially the model taught itself to “think” because that was the best way to score well on the tasks!
In simple terms: RL training for reasoning is like telling the AI “I won’t tell you how to solve it, but I’ll give you a thumbs up when you get it right. So go figure out a method that works.” Amazingly, the AI eventually figures out “hey, breaking the problem into steps and checking my work gets me more thumbs up!” and it adopts that as a strategy. It’s quite an elegant way to train, because we’re not hand-coding logic or spoon-feeding too many examples – we’re just setting up the game, and the AI is learning the rules of reasoning by playing.
- Process vs Outcome Supervision: A quick nerdy detour – within reinforcement learning or feedback-based training, there are two ways to measure success: you can reward the final outcome only (did it get the correct answer?), or you can also reward the intermediate steps (the process). Researchers have found that giving feedback on each step (“process supervision”) leads to better reasoning performance than just feedback on the final answer (“outcome supervision”). Intuitively, it makes sense: if the model only knows whether the final answer was right or wrong, it could stumble in many ways internally and not know which part of its reasoning led it astray. But if it gets finer-grained feedback (like “Step 3 of your reasoning is where you went off track”), it can adjust that specific part of its thinking process. OpenAI experimented with this in training models on math problems and concluded that step-level feedback significantly outperformed just answer-level feedback. Of course, giving feedback on each step is labor-intensive – it often means humans have to label a lot of reasoning steps as good or bad – but it appears to make the AI much better at reliably solving problems.
- Reinforcement Learning from Human Feedback (RLHF): This is a specific flavor of RL used by OpenAI and others to align models with what users prefer. It’s not only about reasoning; it’s also about being helpful, honest, and harmless. However, it does tie in here: after initially training a model (with supervised learning or RL on tasks), developers often use RLHF to fine-tune the model’s behavior to be more user-friendly. For reasoning models, one RLHF step might involve encouraging the model to keep its reasoning focused and not overly long or rambly, or to avoid using unnecessarily complicated steps. Essentially, once a model knows how to reason, you still want to align that reasoning with human preferences (e.g. make the explanations clear, ensure the model doesn’t go off on a tangent or output something misleading). DeepSeek-R1’s full training pipeline, for instance, had multiple stages – they first let the model explore reasoning via RL (even if it led to some messy outputs), and later they aligned and cleaned it up with additional fine-tuning and RLHF-like stages huggingface.co. The end result was a model that both excels at reasoning and produces readable, helpful answers (no more “endless rambling or language mixing,” which the raw RL model sometimes did).
- Distillation (Teaching Smaller Models): One exciting aspect of reasoning models is that once you train a big model to reason well, you can use it to train smaller models – a process called distillation. It’s like having a top student and then coaching the rest of the class using that student’s solutions as examples. The large model’s chain-of-thought outputs can be treated as an answer key for training a smaller model on the same tasks. DeepSeek did exactly this: after training their large R1 model (with 37B active parameters) to be a reasoning whiz, they generated a ton of reasoning data from it and fine-tuned smaller models (1.5B, 7B, 14B, etc.) on that data. The outcome? Those smaller models became far better at reasoning than if you had tried to train them from scratch on the tasks. In fact, DeepSeek’s 32B distilled model outperformed a comparable OpenAI model (o1-mini) on various benchmarks. This shows that reasoning ability can be compressed and passed down – smaller AI students can learn the tricks of their larger teacher. Distillation is super important for making reasoning AI more accessible, because not everyone can run a gigantic 70B+ parameter model with huge compute needs. If you can get a 7B model to reason decently by training it on traces from a 70B model, that opens the door for more developers to use these models (even on ordinary hardware, or at lower cost).
That was a lot of technical ground covered. If you lost track: the key idea is that training a reasoning model involves either showing it how to reason (with examples) or letting it discover reasoning (with trial-and-error rewards), or a mix of both. In practice, teams often combine methods. For example, they might do a bit of supervised fine-tuning to give the model a “head start” in reasoning, then do reinforcement learning to really let it polish its problem-solving skills. There’s also often a final alignment tuning (RLHF) to ensure the model’s reasoning and responses are aligned with human expectations (not too slow, not going into weird irrelevant tangents, etc.).
Now, let’s look at how some prominent AI models and research projects have implemented these ideas – each with their own twist – and compare their approaches.
A Tour of Reasoning Models and Architectures
In the past couple of years, we’ve seen multiple organizations develop reasoning-augmented LLMs. They all share the general idea of chain-of-thought reasoning, but differ in architecture and training details. Here we’ll compare a few notable ones: DeepSeek-R1 (an open project), OpenAI’s models (like GPT-4 and the “o1” reasoning model), Meta’s LLaMA-based models, and a bit about other emerging players. Don’t worry – we’ll keep it high-level enough to follow, highlighting the key differences without drowning in too much jargon.
DeepSeek-R1: Reinforcement Learning to the Rescue
Figure: Benchmark results for DeepSeek-R1, showing its strong performance on reasoning-heavy tasks (math, coding, knowledge tests) compared to OpenAI’s models. This open-source model demonstrated that even smaller-scale efforts can achieve near state-of-the-art reasoning ability with the right training strategy.
What it is: DeepSeek-R1 is an open-source “first-generation reasoning model” introduced in early 2025 by the startup DeepSeek-AI. It gained notoriety for achieving performance comparable to OpenAI’s top models on math, coding, and logic benchmarks – despite being developed with a fraction of the computing resources. In fact, according to the company, R1 performs on par with OpenAI’s much larger models on certain benchmarks, but was trained using far fewer specialized chips and is around 96% cheaper to run than those proprietary models. This made a lot of folks in AI sit up and take notice!
How it works: The secret sauce of DeepSeek-R1 is reinforcement learning at scale. Unlike most previous models that relied on heavy supervised fine-tuning on human-written solutions, DeepSeek-R1’s team boldly started with pure RL. They took a base language model and directly trained it on a variety of reasoning tasks (math word problems, coding challenges, etc.), rewarding it for correct solutions. This model, called DeepSeek-R1-Zero, was essentially learning to solve problems by trial and error, with no initial examples to imitate. Remarkably, it worked – R1-Zero began demonstrating complex reasoning behaviors: it would generate long chains of thought, attempt to self-verify answers, and even reflect on problems in ways that looked very “cognitive”. It was the first open demonstration that an LLM can figure out reasoning by itself if given a suitable reward and enough training.
That said, R1-Zero wasn’t perfect. Because it wasn’t guided at all by human examples initially, some of its outputs were not so user-friendly – e.g. it could produce confusing rambles or mix languages in its answers. The DeepSeek team addressed this by introducing a more structured training pipeline for the final DeepSeek-R1 model. They added a “cold start” phase with supervised fine-tuning on curated data to give the model a solid foundation in both reasoning and general language use. In simpler terms, before letting the model loose with RL, they first taught it, “Here’s roughly how you should talk and solve things” through examples (covering both reasoning steps and normal Q&A). Then they did two stages of RL: one to push the boundaries of its reasoning skill (discover even better problem-solving strategies), and another to align those strategies with what humans prefer (making sure the reasoning is correct and the answers are well-formatted and sensible). This multi-stage approach gave the best of both worlds: the model learned powerful reasoning methods via exploration, but also learned to avoid the gibberish or tangents that pure exploration produced, thanks to a bit of human guidance and preference alignment.
DeepSeek-R1 didn’t stop at making one big model. They were keen to “democratize” reasoning AI (a value shared by many in the open-source AI community). They used distillation (described earlier) to transfer R1’s skills into a whole roster of smaller models. They released checkpoints from 1.5B parameters up to 70B that were fine-tuned on the reasoning data generated by R1. Some of these distilled models (for example, a 32B model based on Qwen, a Chinese LLM) actually outperformed a comparable OpenAI model on benchmarks – setting new state-of-the-art results for models of that size. The takeaway: small models can be taught to think big! By open-sourcing these models under permissive licenses, DeepSeek enabled researchers and developers worldwide to experiment with advanced reasoning AI without needing supercomputers or million-dollar budgets. This open approach – releasing both the code and model weights – has been lauded as a way to accelerate innovation and “AI democratization”, since anyone can build upon the work.
On the technical architecture side, DeepSeek-R1 is interesting too. The base model (DeepSeek-V3) uses a Mixture-of-Experts (MoE) architecture. Without diving too deep into tech: MoE models have a very large number of parameters (DeepSeek-V3 is listed as 671 billion total) but only activate a subset of those (“experts”) for any given query. This means at inference time it might behave like a ~37B parameter model in terms of computation, while leveraging specialized expert subnetworks for different tasks. MoE can greatly improve training efficiency and speed because you don’t have to run the entire network for each input – just the parts most relevant. It’s one way DeepSeek achieved high performance with fewer GPUs. (MoE is a trend that others, like Google’s MoE models and recent efforts by Meta and IBM, have also explored to get more oomph from limited hardware.)
In summary, DeepSeek-R1 showcases an open, cost-effective path to a reasoning AI: use clever training (RL + a dash of human guidance) and clever architecture (Mixture-of-Experts) to produce a model that punches above its weight. It’s a bit like a small startup judo-flipping the giants. And indeed, R1’s release caused quite a stir, making people re-think whether only the biggest tech companies with infinite budgets can build the best AI.
OpenAI’s GPT-4 and “o1”: From Generalist to Specialist
Next, let’s talk about OpenAI’s approach, which in many ways paved the path and set benchmarks in this space. OpenAI hasn’t open-sourced their models, so we often learn about their methods through research papers and snippets shared by their team. The two relevant models here are GPT-4 (OpenAI’s flagship large model, introduced 2023) and an enhanced variant often referred to as “o1” (a reasoning-optimized model they previewed in late 2024).
GPT-4’s hidden reasoning skills: GPT-4 is a large (reportedly very large) multimodal model that was trained on a ton of data (text and code) and then fine-tuned with human feedback (RLHF) to be super useful in dialogues. While not explicitly a “reasoning-only” model, GPT-4 showed a massive leap in reasoning ability compared to its predecessor GPT-3.5. Why? Likely a combination of factors: it was trained on a lot of programming and math-related data (which teaches step-by-step thinking), it’s just larger and more advanced in architecture, and OpenAI may have included some supervised fine-tuning on problem-solving data. Users quickly found that GPT-4 could solve complex math word problems, write code, and explain jokes – all tasks requiring reasoning. With the right prompting (“let’s think step by step…”), GPT-4 could generate detailed chains-of-thought and tackle problems that stumped earlier models. In short, GPT-4 was a general-purpose model with emergent reasoning capabilities – even if it wasn’t specifically trained to always show its work.
The “o1” model – reasoning turned up to eleven: In September 2024, OpenAI gave a peek at a model nicknamed o1 (the exact naming is a bit opaque, but think of it as an experimental cousin of GPT-4) which was specifically tuned for chain-of-thought reasoning. This was something new: unlike GPT-4 which would only reason extensively if prompted, o1 was described as being trained to automatically use chain-of-thought for difficult problems. Essentially, OpenAI took the approach of “let’s not rely on the user to prompt the reasoning; let’s have the model always do the reasoning internally for complex questions.”
How did they achieve this? From what was shared, they used reinforcement learning focused on reasoning tasks (sounds familiar, right?) to train o1. They likely started with a strong base (GPT-4 or something similar) and then did additional training where the model gets rewarded for solving challenging multi-step problems. Over time, the model learns to “slow itself down” and apply a chain-of-thought approach because that wins the reward game.
OpenAI noted that through this process, the model “learns to hone its chain of thought and refine its strategies. It learns to recognize and correct mistakes, break down tricky steps, and try different approaches when stuck, which dramatically improves its reasoning ability.” This description is essentially the same kind of behavior DeepSeek saw – the model becomes more like a diligent problem-solver than a quick guesser.
One interesting aspect reported by OpenAI’s team: when a question doesn’t actually need heavy reasoning, the o1 model was not significantly better than the regular GPT-4 (and was slower). This makes sense – if the task is easy or something like casual chatting, the chain-of-thought is overhead. So GPT-4 (or an “GPT-4 fast mode”) could answer such things more efficiently, whereas o1 shines on the hard stuff. This implies that in practice, one might use a mix: default to the fast general model for easy queries, but bring out the big reasoner for complex ones.
OpenAI’s research also emphasized the value of process supervision (giving feedback on steps, as discussed) in training their models for reliability. They even built a system where humans labeled thousands of step-by-step solutions for math problems (creating a dataset called PRM800k) so they could train reward models to judge each step. They found that this approach led to models that make far fewer logical mistakes. Additionally, to reduce the burden on human raters, OpenAI developed an AI-based helper called CriticGPT – essentially a GPT-4 fine-tuned to be a code and solution critic – to automatically spot errors in the model’s reasoning steps. This kind of AI assisting AI setup hints at the future of training: models that help train other models by providing intermediate feedback.
In summary, OpenAI’s strategy for reasoning can be seen as “take a powerful base model and make it even better at reasoning through targeted training (with RL and step-by-step feedback).” The result (o1) was a model that doesn’t need prompt engineering to reason; it just does it. This was a paradigm shift that validated what the community suspected: that scaling computation at inference time (i.e. letting the model think more per query) can be as important as scaling the model size itself. Or in simpler terms, making the model smarter isn’t just about making it bigger or training on more data – it’s also about teaching it to use its brainpower more effectively when answering.
LLaMA and Other Open Models: Foundations and Fine-Tuning
Meta’s LLaMA models (LLaMA 1, and the improved LLaMA 2) are another cornerstone of the AI landscape. These models were released publicly (LLaMA 2 is fully open-source) and have sizes ranging from 7B to 70B parameters. Out-of-the-box, a LLaMA is trained on a broad set of internet text, code, etc. It’s a strong foundation model, but by itself it’s not explicitly a “reasoning model”. It knows a lot and can do some reasoning, but it wasn’t specifically taught to always show work. In fact, the original LLaMA (7B or 13B) struggled with complex reasoning tasks unless you primed it well, simply because it wasn’t as large as GPT-4 and didn’t undergo the same specialized training.
However, the open-source community quickly took LLaMA and fine-tuned it for various purposes – including reasoning tasks. For example, there have been community models like WizardMath (a LLaMA 2 70B fine-tuned on math problems with chain-of-thought solutions) and others targeting coding, logical puzzles, etc. By fine-tuning on high-quality reasoning datasets (some of which are created by distilling from GPT-4’s outputs), these LLaMA variants significantly close the gap in reasoning ability. It’s akin to how DeepSeek distilled their model into LLaMA-based checkpoints. The recipe is: start with a good base (LLaMA, which has strong general language understanding), then train on examples of reasoning or use RL with it on reasoning challenges. The result is a more specialized model that can solve math word problems, programming challenges, etc., much better than the base model could.
One advantage of open models like LLaMA is customizability. An AI research lab or even an individual developer can take a LLaMA weight and apply techniques like LoRA (Low-Rank Adaptation) to fine-tune it on their specific type of reasoning problem with modest compute. This democratizes the development of niche reasoning models – say a biomedical reasoning model that is good at medical diagnosis logic, or a legal reasoning model for analyzing case law – without having to train a giant model from scratch. We’ve also seen companies like Alibaba (with their Qwen models) and others release foundation models and then fine-tune or distill them for reasoning tasks (Alibaba’s Qwen-2.5 has a Math-specialized variant, which was used in DeepSeek’s distillation pipeline).
In terms of architecture, LLaMA models are standard dense transformers (no fancy MoE here). That means they activate all their neurons for every token. This makes them somewhat hardware-intensive at large scales, but also straightforward to use. The open-source world has gotten very good at optimizing these models with techniques like quantization (reducing precision to fit on smaller GPUs) and distributed sharding. So even though a 70B LLaMA is big, people have managed to run them on a single high-end GPU or a few of them, which is impressive. Still, if you want the very best reasoning performance, you’d either use the largest open models fine-tuned for the task, or leverage an MoE-based giant like DeepSeek if you have the resources.
How do they compare? In broad strokes:
- OpenAI GPT-4 (base) – extremely capable generally, shows strong reasoning especially when prompted to do chain-of-thought. Closed source, and the full model is not accessible for self-hosting.
- OpenAI o1 (reasoning-optimized) – presumably built on GPT-4, with RL training to make chain-of-thought automatic. Even better at reasoning tasks, but slower per query. (Not publicly available to use as of writing; it was a preview of where things are heading).
- DeepSeek-R1 – an open model explicitly trained via RL to be a great reasoner. Competitive with the above on many tasks. Its full version is huge (with MoE), but you can use distilled smaller versions. Openly released.
- LLaMA-based fine-tunes – many options here, like LLaMA-65B fine-tuned on math, etc. Their performance can be very good, though often not quite at GPT-4 level for the hardest problems unless a lot of distillation from GPT-4 was involved. However, they are improving rapidly as community builds better datasets (often by having GPT-4 or DeepSeek generate high-quality solutions as training data).
One more player to mention is Anthropic’s Claude models. Claude is another large language model (by Anthropic) that was trained with an emphasis on being helpful, honest, and harmless. It wasn’t specifically a “reasoning model,” but Anthropic did a lot of research on making models follow principles and not hallucinate. They explored ideas like constitutional AI (where the AI critiques and improves its own answers). While Claude hasn’t been advertised as doing chain-of-thought internally, it is quite good at reasoning tasks when prompted, likely due to the massive training on dialogue and some safety-related reasoning tasks.
And then we have Google’s efforts – Google’s Pathways and Gemini (the successor to PaLM, rumored to combine DeepMind’s reinforcement learning know-how with large language models). Google’s PaLM 2 model (used in Bard as of 2023) had decent reasoning, especially in coding, but it wasn’t as consistent as GPT-4. With DeepMind’s influence (recall DeepMind built AlphaGo and other agents using RL), the upcoming Gemini model is expected to heavily feature reasoning abilities and perhaps even tool use integration. Google has also experimented with their own chain-of-thought fine-tuning (e.g., the Minerva model was a PaLM fine-tuned on math text with solutions, making it a math specialist).
Meanwhile, ByteDance (the company behind TikTok) made news with a model called UI-TARS, described as a “reasoning agent” that can even look at a graphical interface and take step-by-step actions. They claimed it outperformed GPT-4, Claude, and Google’s Gemini (early version) on certain benchmarks. This hints that the concept of reasoning models isn’t limited to text problems – it extends to agents that can plan and act in environments (like reading a webpage and clicking buttons to accomplish a task). UI-TARS doing “autonomous, step-by-step action” with reasoning is like an AI that not only thinks out a solution but also executes a sequence of operations to achieve a goal. That’s a bit beyond pure language modeling and ventures into the territory of AI agents (think ChatGPT plugins or AutoGPT-style systems, but with a robust reasoning brain). It’s an exciting direction where reasoning models become the decision-making core of autonomous systems.
To wrap up this tour: we see a common theme of chain-of-thought + some form of feedback learning across the board. The differences are often in scale, openness, and specific techniques:
- OpenAI uses massive scale and lots of human feedback (including process supervision).
- DeepSeek uses massive (but efficient MoE) scale with pure RL and open-sources everything.
- Meta’s open models rely on community fine-tuning and distillation to gain reasoning prowess.
- Others like ByteDance and Google are blending reasoning with action and multi-modality.
It’s a rapidly evolving area, and the gap between open models and closed models in reasoning ability has been shrinking thanks to these innovations. In fact, by open-sourcing reasoning models and their training data, researchers are collaboratively finding what works best, and even big companies benefit from those insights.
The Friendly Explainer: Reasoning Models for Everyone
Let’s pause the tech talk for a moment. How would we explain reasoning models to someone without an AI background – say a kid, or your friend who just knows Siri and Alexa? Probably like this:
Think about how you solve a hard puzzle. You don’t just blurt out an answer; you think it through step by step. Maybe you draw little diagrams, or do some scratch calculations. If you get stuck, you try a different way. If you find a mistake, you go back and fix it. Eventually, you get the answer and you’re confident because you checked your work.
Now imagine your smart computer buddy (the AI) doing the same thing. That’s a reasoning model. It’s an AI that, instead of instantly giving an answer, will take a moment to figure things out. It’s like having an AI that’s not just knowledgeable, but also smart in how it uses its knowledge – almost like it has a bit of common sense or problem-solving skill, not just memorized facts.
For a long time, computers didn’t really do this. They either knew the answer or they didn’t, and if they tried to explain, it was usually just a guess. But now, we’ve taught some AIs to actually work through the problem internally. They can write out a little solution path (sometimes we can even peek at it). If they realize something doesn’t add up, they can correct themselves, kind of like how you would erase a step in your homework and redo it.
This makes them much better at tricky questions or multi-step problems. It’s the difference between an AI that just remembers things, and an AI that can solve new problems by reasoning. Pretty cool, right? It’s like the AI has learned not just facts, but how to think logically. So next time you hear an AI explaining its answer, or solving a math problem with multiple steps, you’re likely seeing a reasoning model in action – your computer buddy showing its work, just like your teacher always said you should!
*(And if the kid asks “how do they learn that?”, you might say: We train them a bit like training a dog or playing a game. We give the AI a treat (a reward) when it gets the answer right, especially when it shows the right steps. Over time, the AI figures out that doing those careful steps gets more treats. So it learns to always do the careful steps. In real life it’s more complex, but that’s the basic idea!) *
Why Do Reasoning Models Matter?
By now, you might be thinking, “This is neat, but do we really need AIs to think out loud? Isn’t it faster if they just answer straight away?” It turns out, reasoning models fill an important gap and address several issues that traditional AI models face:
- Accuracy on Complex Tasks: For questions that involve multiple pieces of information or tricky logic, vanilla AI models often stumble or hallucinate incorrect answers. Reasoning models are far more reliable on complex tasks like multi-step math problems, logical riddles, or code generation that requires planning. In coding, for example, a reasoning AI can plan out what it needs to do, write code, then self-check that code for errors. This leads to much higher success rates on difficult coding challenges. In one internal test, OpenAI noted that when their model was trained to reason (o1), it could solve hard problems that GPT-4 could not, simply because GPT-4 would make a mistake and not realize it, whereas o1 would catch and correct the mistake in the process.
- Transparency and Trust: A big issue with AI is you often don’t know why it gave an answer. If an AI assistant says “The answer is 42,” you have to either trust it or not, with no insight into its reasoning. With chain-of-thought, we can inspect the reasoning (at least, whatever the model claims as its reasoning) which helps in debugging and understanding the AI’s thought process. If the reasoning looks wrong, we can choose not to trust the answer. Think of it like showing your work on a math test – the teacher (or user) can follow your solution and spot where you went wrong, rather than just seeing the final answer. This could make it easier to identify AI mistakes or biases. That said, we must remember the chain-of-thought is generated by the model and could potentially be misleading at times (the model might still make a mistake in its reasoning, or even hide a step). Research is ongoing into how to ensure the reasoning traces are faithful. But generally, having that trace is an improvement over pure black-box answers.
- Instruction Following and Deliberation: Reasoning models tend to be better at following complicated instructions. If you ask a reasoning-enabled AI something like, “Plan a weekend trip for me, making sure to account for weather, budget, and my preference for historical sites. Explain your thinking,” a reasoning model will methodically go through each requirement, perhaps list options, weigh pros and cons, and come to a conclusion. A regular model might give you a generic answer that doesn’t deeply consider each part. The ability to deliberate internally means the AI can handle more nuance. In fact, some researchers talk about using reasoning models for “better alignment” – by letting the model reason about the ethical or safety implications of a query internally, you might get safer and more considered response. (OpenAI has discussed concepts like “deliberative alignment,” where the model uses a chain-of-thought to check if an action is in line with safety rules.)
- Reaching Superhuman Problem-Solving: For certain tasks like complex mathematics, code optimization, or planning, reasoning models open a path to performance that even experts might struggle to match, because the AI can rigorously explore possibilities. We’ve already seen glimpses of this: models solving difficult Olympiad-level math problems, writing novel algorithms, or proving theorems. When combined with tool use (e.g., calling a calculator or running code as part of its reasoning), an AI can have virtually infinite patience to work through a problem. Chain-of-thought gives it a structure to do so. This doesn’t mean AIs are universally smarter – but in narrow domains, a well-trained reasoning model coupled with computational tools could surpass human capabilities (just as calculators did for arithmetic, but now for reasoning tasks).
- Ease of Debugging AI: If an AI does something wrong, having it produce a reasoning log can help engineers figure out which part of the model’s thought process led to the error. This can guide improvements. It’s analogous to looking at a program’s trace or a car’s black-box recorder. For instance, if a reasoning model playing an analytic game (say solving a puzzle) arrives at a wrong answer, you can see which step was flawed. That might point to a concept the model didn’t fully grasp, which could be addressed by giving it more training examples for that specific reasoning pattern.
A Peek into the Future
AI is rapidly evolving, and reasoning models are at the forefront of making AI more capable and trustworthy. What might we expect moving forward?
- More Hybrid Models: We’ll likely see more systems that combine reasoning with action. Think of an AI that not only figures out what to do, but can also do it. For example, a reasoning model controlling a household robot might internally reason through a task (“Step 1: go to kitchen; Step 2: open fridge; Step 3: if no milk, check pantry…”) and then execute those steps. Early versions of this exist in research (like the aforementioned UI-TARS that can read UIs and act, or various “AI agents” that use language models to plan actions). The boundary between pure language reasoning and embodied or tool-using AI will blur. We’ll have AIs that can plan like a general and act like a soldier, so to speak.
- Efficiency Improvements: Reasoning tends to slow down responses (all that extra thinking). Researchers will keep working on making this more efficient. One idea is adaptive computation: the model could learn to only do as much reasoning as needed. If it’s a simple question, it uses minimal steps; if it’s hard, it uses more. This way you get the best of both – speed and brains when each matter. Already, some models can adjust their “chain-of-thought length” dynamically, and future architectures might support this more explicitly (imagine a model that can allocate more computing resources on the fly for tougher problems).
- Better Training Data for Reasoning: The community is generating larger and higher-quality datasets of solutions and reasoning steps. This includes human-written explanations (like textbook solutions, tutorial content) and AI-generated ones (e.g. using GPT-4 to create reasoning data for fine-tuning smaller models). As these datasets grow, even relatively small models can be taught to emulate reasoning by supervised training on them. This might lower the barrier so you don’t always need heavy reinforcement learning – instead, a clever combination of synthetic data generation and selective fine-tuning could produce surprisingly good reasoners.
- Interpretable and Trustworthy AI: With reasoning models, we inch closer to AI that can justify its answers in human-like ways. This is crucial for trust. Imagine using an AI doctor – you’d want it to explain why it diagnosed something, not just pronounce the diagnosis. A reasoning model could list the symptoms, the medical reasoning (“symptom X and Y together often indicate condition Z because…”) and then conclude. As long as that reasoning is correct, it gives the user confidence and understanding. We do need to ensure the reasoning isn’t just plausible-sounding but actually correct – a challenge known as grounding. We don’t want an AI that can explain incorrectly very convincingly. Ongoing research focuses on verifying each step of the AI’s reasoning (even using other AIs as critics or validators) to ensure the chain-of-thought is sound. In the future, your AI assistant might not only give you answers but also engage in a dialogue about its reasoning – letting you probe and ask “Hey, why did you think that?” and it will clarify. This could greatly improve human-AI collaboration.
- Broader Accessibility: Thanks to open-source efforts (like DeepSeek, LLaMA community, etc.), these advanced capabilities won’t be confined to a few tech giants. We can expect more open reasoning models that anyone can run on their own devices or servers. As one IBM researcher noted, open-source reasoning models like DeepSeek-R1 “could really accelerate AI democratization.” We might even see efficient reasoning models that can run on a smartphone or laptop – there’s active work on optimizing models and using techniques like MoE or quantization to shrink the required compute without losing too much capability. Just as today we have smaller versions of chatbots that can run offline for privacy, tomorrow we might have a mini reasoning AI on your phone helping you plan your schedule or solve a puzzle, all without needing to send data to the cloud.
- Multimodal Reasoning: So far we talked mostly about text-based reasoning (solving problems described in words, code or math). But reasoning models will extend to other modalities: vision, audio, etc. For instance, an AI that analyzes an image to answer a question might benefit from reasoning (“I see a set of keys on the table and an open door, logically the person might have just come home…”). Or a robot reasoning about physical space (that’s a bit like planning, which is reasoning in action). Google’s Gemini is rumored to integrate vision and text with strong reasoning. We already have GPT-4’s vision component that can analyze images with some reasoning (e.g., explaining a meme by connecting visual cues to abstract concepts – that’s reasoning!). So the future will have AIs that reason across text, images, and beyond, allowing more complex tasks like interpreting diagrams, troubleshooting machinery from sensor data, or composing a scene in a design.
In essence, reasoning models represent a move towards AI that is more thoughtful, reliable, and versatile. Instead of shallow question-answering, we’re teaching machines deeper problem-solving skills. It’s an ongoing journey – current models still make mistakes and can be slow – but the progress in just the last couple of years has been incredible. From discovering that prompting helps, to RL-crafted reasoners that rival top models, to distilling those skills into everyday devices, we’re witnessing AI learn to think step-by-step.
Conclusion
We started with a simple idea: get AI to show its work. We end with the realization that this idea is transforming how AI is built and what it’s capable of. Reasoning models like DeepSeek-R1, OpenAI’s GPT-4 (with its chain-of-thought training), and open-source LLaMA offshoots are proving that large language models can do more than predict the next word – they can learn to reason through complex challenges. By combining techniques like chain-of-thought prompting, supervised fine-tuning on solutions, and reinforcement learning with feedback, we’ve unlocked a new level of AI performance on tasks that require logic, planning, and multi-step deduction.
For developers and tech leaders, understanding how these models work isn’t just intellectually satisfying – it’s practical. It means knowing how to get the most out of AI systems (e.g. by eliciting reasoning when needed), how to fine-tune models for domain-specific reasoning, and how to interpret model outputs that include rationales. It also means being aware of the trade-offs: a highly reasoning-focused model might be slower or more verbose, so you’d use it when accuracy on a hard problem matters more than speed, much like you’d choose a careful senior engineer over an impulsive junior one for a delicate task.
We made the content conversational and approachable because, at its core, the concept of a machine thinking out loud is something anyone can grasp. It connects to how we humans solve problems. As AI becomes a bigger part of everyday life, these human-like traits – explaining decisions, checking its work – will make interactions smoother and outcomes more trustworthy.
The field is moving fast. Today’s cutting-edge ideas (like process supervision, or reasoning+acting agents) could become standard practice tomorrow. But the intuition you’ve hopefully gained from this guide will remain relevant: when you hear about the next big AI model, you might ask, “Does it use reasoning? How was it trained to think?” – and you’ll have a framework to understand the answer.
In the end, an AI that can reason is less of a mystery box and more of a tool we can collaborate with. And as these models continue to improve, who knows – the phrase “let’s think this through together” might apply not just to two people, but to you and your AI assistant solving a problem hand-in-hand. That’s the future we’re headed towards, and it’s equal parts exciting and empowering.
Tega AdeyemiJune 25, 2025