
Below is a “one-stop” beginner-friendly tour of Mixture-of-Experts (MoE) for busy developers and AI leaders. We’ll demystify the idea, show why VPs keep talking about it, walk through hands-on PyTorch, Hugging Face, and DeepSpeed examples, and flag the gotchas that bite most first-time adopters. If you’ve heard that Mixtral, Switch Transformer or GLaM squeeze GPT-3-class quality out of a fraction of the compute and wondered “how?” — this guide is for you.
1 What is a Mixture of Experts, really?
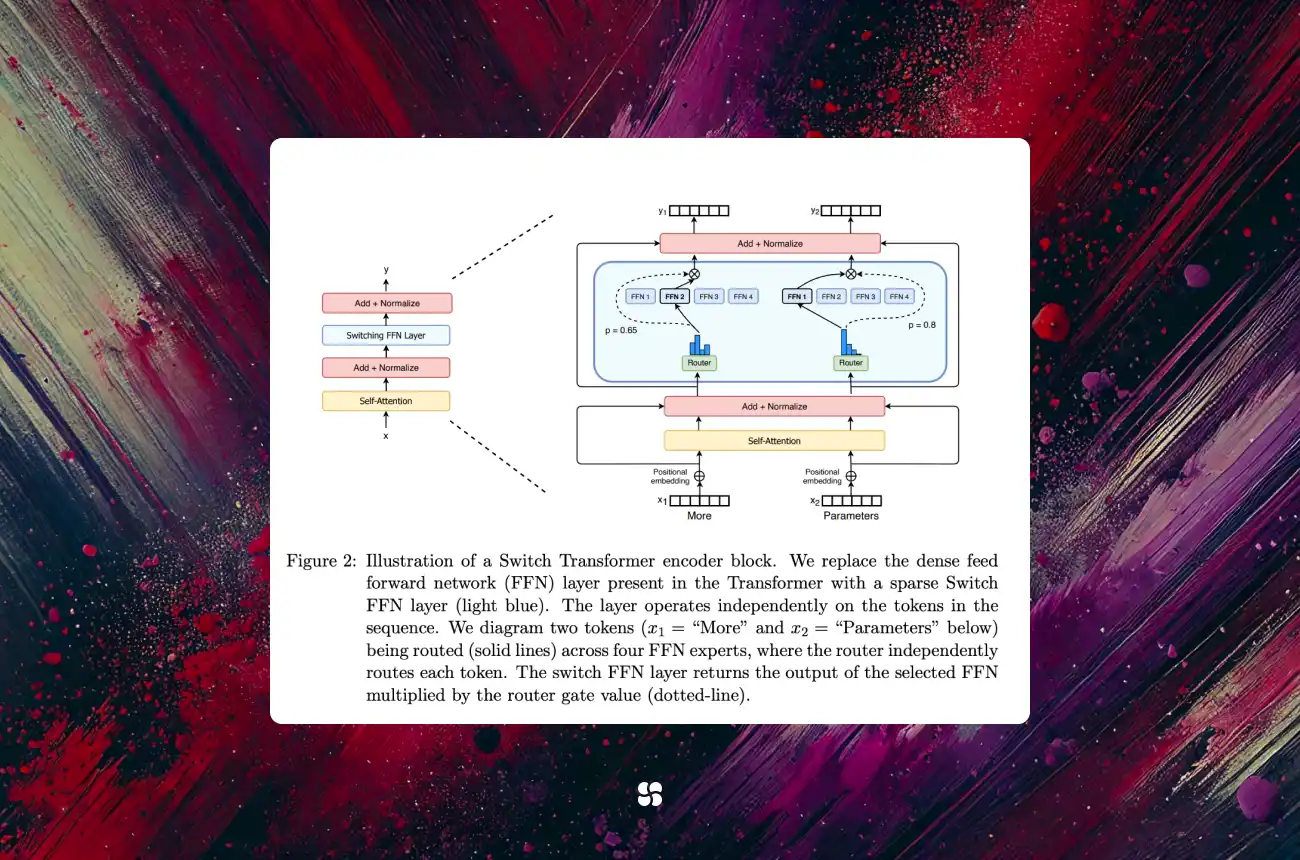
A MoE layer replaces the plain feed-forward block inside a Transformer with N parallel subnetworks called experts.
For every token, a tiny learned router picks the top-k experts and combines their outputs, so only a small slice of parameters fires per example — sparse activation without sacrificing capacity.
Where did it come from? The idea dates back to 1991’s “Adaptive Mixture of Local Experts,” but it re-entered the limelight when Google’s Switch Transformer hit 1 trillion parameters with 7× faster pre-training on the same hardware arxiv.org. Subsequent milestones include GShard’s 600 B-parameter translator arxiv.org, GLaM’s top-2 routing arxiv.org, and the open-weight Mixtral 8×7B family that popularised SMoE in the OSS world mistral.ai.
2 Why executives care: scale economics in plain English
| MoE win | Real-world evidence |
|---|---|
| Decouple compute from params | GShard grew model size 16× while only 3.6× more TPU core-years were needed |
| Greener training | GLaM matched GPT-3 quality using a third of the energy budget [arxiv.org] |
| Faster wall-clock pre-train | Switch pre-trained 7× faster than dense T5 on identical chips [arxiv.org] |
| Competitive inference latency | DeepSpeed-MoE shows super-linear throughput scaling while keeping latency in check [deepspeed.ai] |
| Fit on commodity GPUs | MoE-Infinity keeps experts on host RAM and streams them just-in-time for generation [github.com] |
CAP-trade-off reality check: recent MoE-CAP benchmarks show you rarely optimise Cost, Accuracy and Performance simultaneously; you usually pick twoarxiv.org.
3 Under the hood
3.1 Anatomy
- Experts – often standard FFNs; they specialise during training.
- Router/Gate – softmax over experts; common policies: top-1 (Switch) or top-2 (GLaM).
- Auxiliary losses – e.g. load-balancing and Z-loss to stop one expert hogging all tokenshuggingface.co.
3.2 Routing innovations
- Expert Choice (EC) routing balances load by letting experts choose tokens rather than the reverseresearch.google.
- Layerwise recurrent routers maintain token-to-expert affinity across layers for better convergencearxiv.org.
3.3 Scaling laws
Fine-grained scaling shows quality keeps improving up to millions of experts, provided routing overhead is tamedarxiv.org.
4 Hands-on: three ways to build an MoE
4.1 From-scratch PyTorch “toy”
import torch, torch.nn as nn, torch.nn.functional as F
class Expert(nn.Module):
def __init__(self, d_model, d_ff):
super().__init__()
self.w1, self.w2 = nn.Linear(d_model, d_ff), nn.Linear(d_ff, d_model)
def forward(self, x): # x: (batch, tokens, d_model)
return self.w2(F.gelu(self.w1(x)))
class SimpleMoE(nn.Module):
def __init__(self, d_model=512, d_ff=2048, n_experts=4, k=2):
super().__init__()
self.experts = nn.ModuleList([Expert(d_model, d_ff) for _ in range(n_experts)])
self.gate = nn.Linear(d_model, n_experts); self.k = k
def forward(self, x):
gate_scores = self.gate(x) # (b, t, nE)
topk_vals, topk_idx = gate_scores.topk(self.k, dim=-1)
weights = topk_vals.softmax(-1) # (b, t, k)
out = torch.zeros_like(x)
for slot in range(self.k):
idx = topk_idx[..., slot] # (b, t)
chosen = torch.stack([self.experts[i](tok) for i, tok in enumerate(
torch.unbind(x, dim=0))]) # naive loop for clarity
out += weights[..., slot:slot+1] * chosen
return outThis minimalist layer shows the core mechanism; production code vectorises routing and runs experts in parallel on different GPUs.
4.2 Hugging Face Transformers quick-start
from transformers import SwitchTransformersConfig, SwitchTransformersForConditionalGeneration
cfg = SwitchTransformersConfig(num_experts=8, router_top_k=2)
model = SwitchTransformersForConditionalGeneration(cfg)SwitchTransformers ships with Router-Z loss, load-balancing loss, and accepts standard generation APIs huggingface.co.
4.3 Training at scale with DeepSpeed
DeepSpeed-MoE wraps expert, data, tensor and ZeRO parallelism behind a single layer API:
import deepspeed, torch.nn as nn
from deepspeed.moe.layer import MoE
class Net(nn.Module):
def __init__(self, hidden):
super().__init__()
self.moe = MoE(hidden_size=hidden,
expert=nn.Linear(hidden, hidden),
num_experts=16, ep_size=4) # 4-GPU expert-parallel groupThe library transparently shards experts, supports BF16, and can combine ZeRO-Offload for GPU-poor rigs — see the tutorial for full recipe.
5 Serving in production
- DeepSpeed-Inference coordinates expert-parallel groups and tensor-slicing to reach super-linear throughput while holding latency flat.
- MoE-Infinity streams dormant experts from CPU RAM, letting Mixtral run on a single 24 GB card (with some patience).
- Cloud vendors increasingly offer expert-parallel TPU slices; pricing follows active-parameter FLOPs, not total params.
6 Common pitfalls & pro tips
| Pain point | Fix |
|---|---|
| Router collapse (one expert gets all tokens) | Add strong load-balancing loss and WarmUp top-k annealing [research.google] |
| OOM from all-experts-in-RAM | Offload inactive experts (MoE-Infinity) or use parameter-efficient resid-MoE (PR-MoE) [deepspeed.ai] |
| Communication bottlenecks | Co-locate experts with tokens; enable all-reduce overlap (DeepSpeed) [deepspeed.ai] |
| Unfair dense vs MoE comparisons | Normalise by training time & tokens seen, not raw parameter count; see MoE-CAP critique [arxiv.org] |
7 Looking ahead
Research is pushing toward million-expert regimes arxiv.org, ever-smarter routers (EC, recurrent, k-means), and hybrid dense-MoE blends that reclaim dense accuracy for reasoning workloads. Meanwhile, industry voices predict MoE and other conditional-compute tricks will replace brute-force scaling as hardware, data and energy ceilings loom.
8 Take-aways
- MoE lets you grow parameters without blowing up FLOPs — ideal for long-context LLMs.
- Real wins come from routing science and system engineering, not just slapping experts into your model.
- Start small (toy PyTorch), graduate to Hugging Face for prototyping, and reach for DeepSpeed or Pathways once you need billions of parameters.
Until the next one,
Tega AdeyemiJune 24, 2025